
9 Priority Queues
Learning Objectives
After reading this chapter you will…
- understand the concept of a priority queue.
- understand the features of heaps, one of the most common priority queue implementations.
- be able to implement Heap Sort, a sorting algorithm that uses a priority queue.
- be able to explain the common operations on priority queues and their complexity.
- be able to implement a binomial heap that supports a fast union operation.
Introduction
We have already discussed the concept of a queue. This is a data structure that accepts items and removes them in the order they were inserted. This is often referred to as first-in-first-out, or FIFO. A priority queue serves like a regular queue allowing items to be inserted, but it allows for the item with the highest priority to exit the queue first. We could implement a priority queue as a simple array with a current capacity that just resorts all the items by priority every time an item is inserted. This would mean that the insert operation for our simple priority queue would be O(n log n). There may be more clever approaches to preserve the sorted order by moving things over. This might lead to an O(n) insert operation. Extract could work similarly by removing the first element and then copying all the elements over. Could we do better than O(n) though? Linear time might be a long time to wait for a large n. For example, suppose many players are waiting to start an online game. We could use a priority queue to add players to the next game based on how long they have been waiting. A game AI may want to prioritize and target players that are the most dangerous first. We will see in chapter 11 that priority queues are used as the foundation for some important graph algorithms. Since this type of data structure could be very useful, researchers and engineers have discovered a variety of data structures that greatly improve the time-cost complexity. We will explore two interesting implementations of priority queues in this chapter.
Heaps
A heap is a data structure that guarantees that the minimum (or maximum) value is easily extracted. The most common heap is a binary heap, which is a sort of binary tree. In a binary heap, the “left” or “right” position of a child node no longer carries any specific meaning. Rather, in a max-binary-heap, or just max-heap, the parent is guaranteed to be greater than both children. Min-binary-heaps naturally reverse that relationship, with the parent guaranteed to be less than the children. We call this quality the heap property. It will allow us to isolate our reasoning to only subheaps and thus aid our understanding of heap-related algorithms.
For the remainder of this section, we assume max-binary-heaps to avoid confusion. We will also assume unique values in our binary heap. This simplifies the relationships between parents and their children. If a particular application of binary heaps necessitates duplicate keys, this is easily remedied by adjusting the appropriate comparisons. The figure below gives an example of a heap:
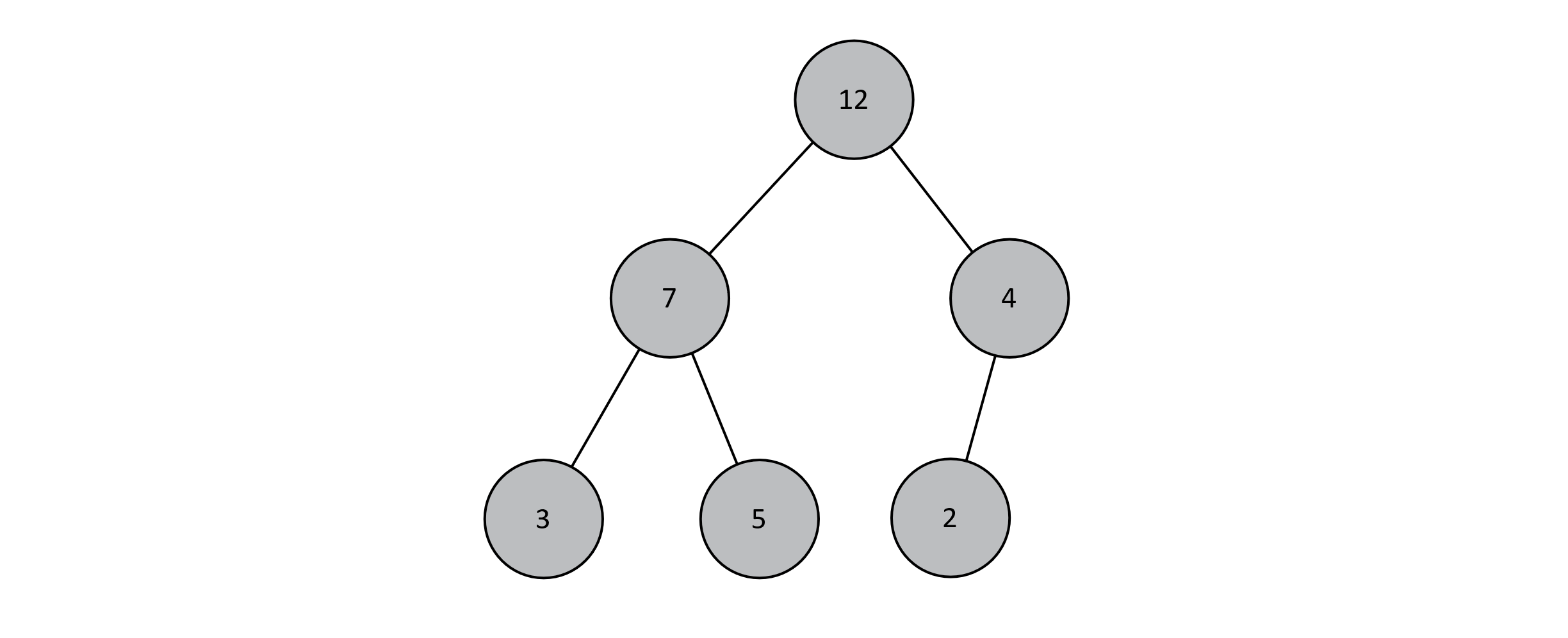
Figure 9.1
This distinction between parent and child nodes leads to two convenient properties of binary heaps:
- For a given heap, the maximum value (or key) is easily accessible at the root of the tree. As we will soon see, this implies not that it is easily extracted from the structure but simply that finding it is trivial.
- For any given node in a binary heap, all descendants contain values less than that node’s value. In other words, any given subtree of a max-binary-heap is also a valid max-binary-heap.
Let us emphasize and further address a common point of confusion. Although binary heaps are binary tree structures, their similarities with binary search trees (BST) end there. Recall from chapter 8 that an in-order traversal of a binary search tree will produce a sorted result. This is true because, for any given node in a BST, all left descendants are less than that node, and all right descendants are greater than it. In binary heaps, the left descendant is less than the parent, and the right descendant is less than it as well, but there is no other defined relationship between the two descendants.
To understand insertion and extraction, first note the shape of the binary tree above. A tree is a complete binary tree if each node has two children and all levels are filled except possibly the last, which is filled from left to right (chapter 8). Using some clever tricks, we can store a complete binary tree as an array. Because each level of the tree is filled and the last is filled left to right, we can simply list all elements in level 0, followed by all elements in level 1, and so on. Once these values are stored in an array, some simple arithmetic on the indexes allows traversal from a node to its parents or its children. We will be regularly adding and removing data from the heap itself. As we have seen in prior chapters, arrays are an insufficient data structure for accomplishing this. For the sake of simplicity, we will assume excess capacity at the end of the array. In practice, we would probably use some sort of abstract list that is able to grow or shrink and provides constant-time lookups. This might be something like an array that automatically reallocates when its capacity is reached. Implementations of these lists exist in most modern languages. For the present discussion, we can just treat the underlying storage as a typical array. The image below shows a heap represented as an array with integer values for the priorities:
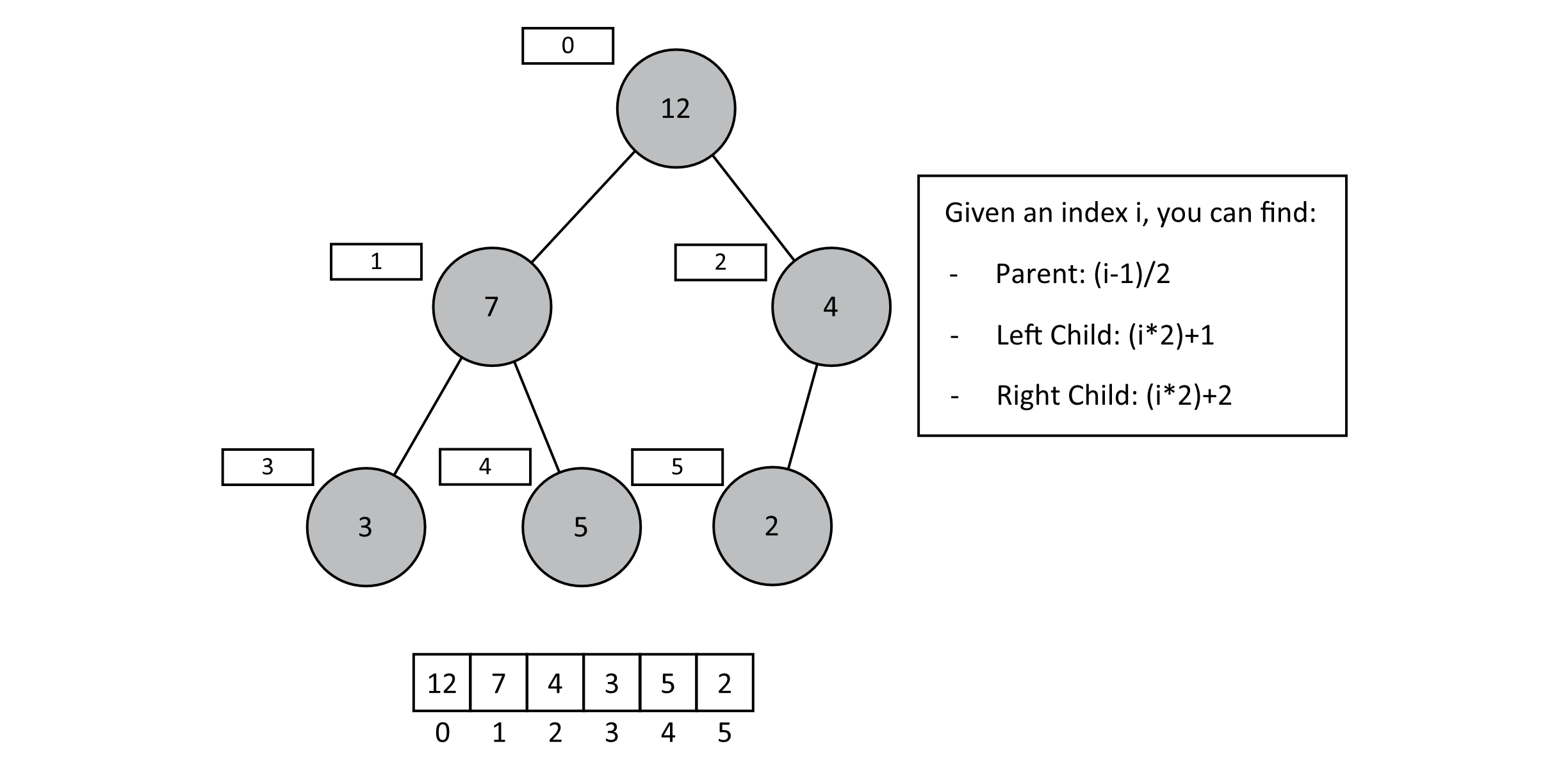
Figure 9.2
For now, we will work only with integers that serve as the priorities themselves. To extend this into a more useful data structure, we would need only to change the contents of the array to an object or object reference. This would allow us to hold a more useful structure such as a student record or a game player’s data. Then the only other change needed would be to do comparisons on array[index].priority instead of just array[index]. This modification is like the one we discussed regarding Linear Search in chapter 4. Recognize that we can generalize this representation easily to accommodate data records that are slightly more sophisticated than just integers.
Operations on Binary Heaps
Before we discuss the general operations on binary heaps, let’s discuss some helper functions that will help us with our array representation. We will define functions that will allow us to find the parent, left child, and right child indexes given the index for any node in the tree structure. These would be helpful to define for any tree structure that we wanted to implement using an array. For this representation, the root will always be at the index 0. These are given in the figure above, but we will provide them as code here:

Here the floor function is the same as the mathematical function floor. It rounds down to the next integer.


Heapify and Sift Up
Using the above functions to access positions in our tree, we can develop two important helper functions that will allow us to modify the tree and work to maintain our heap properties. These are the functions heapify and siftUp. When we are building our heap or modifying the priority of an item, these functions will be useful. The heapify function will exchange a parent with the larger of its children and then recursively heapify the subheap. The siftUp function will exchange a child with its parent to maintain the heap property by moving larger elements up the heap until it either is smaller than its parent or becomes the root node element. The siftUp function will be used when we want to increase the priority of an element. Let’s look at the pseudocode for these functions in the context of an array-based max-heap implementation.
The heapify function below lets a potentially small value work its way down the max-heap to find its correct place in the heap ordering of the tree. This code uses a size parameter that gives the current number of elements in the heap. This code also makes use of an exchange function like the one discussed in chapter 3 on sorting. This simply switches the elements of an array using indexes.

Now we will present the siftUp function. This function works in the reverse direction from heapify. It allows for a node with a potentially large value to make its way up the heap to the correct position to preserve the heap property. Since siftUp moves items toward index 0, the size is not needed. This does assume that the given index is valid.

With these two helper functions, we can now implement the methods to insert elements and remove the max-element from our priority queue. Before we move on though, let’s think about the complexity of these operations. Each of these methods moves items up or down the depths of a binary tree. If the tree could remain balanced, then a traversal from the top to bottom or bottom to top should only require O(log n) operations, assuming that the tree is balanced.
Insertion
Consider inserting the number 8 into the prior binary heap example. Imagine if we simply added that 8 in the array after the 2 (in position 6).
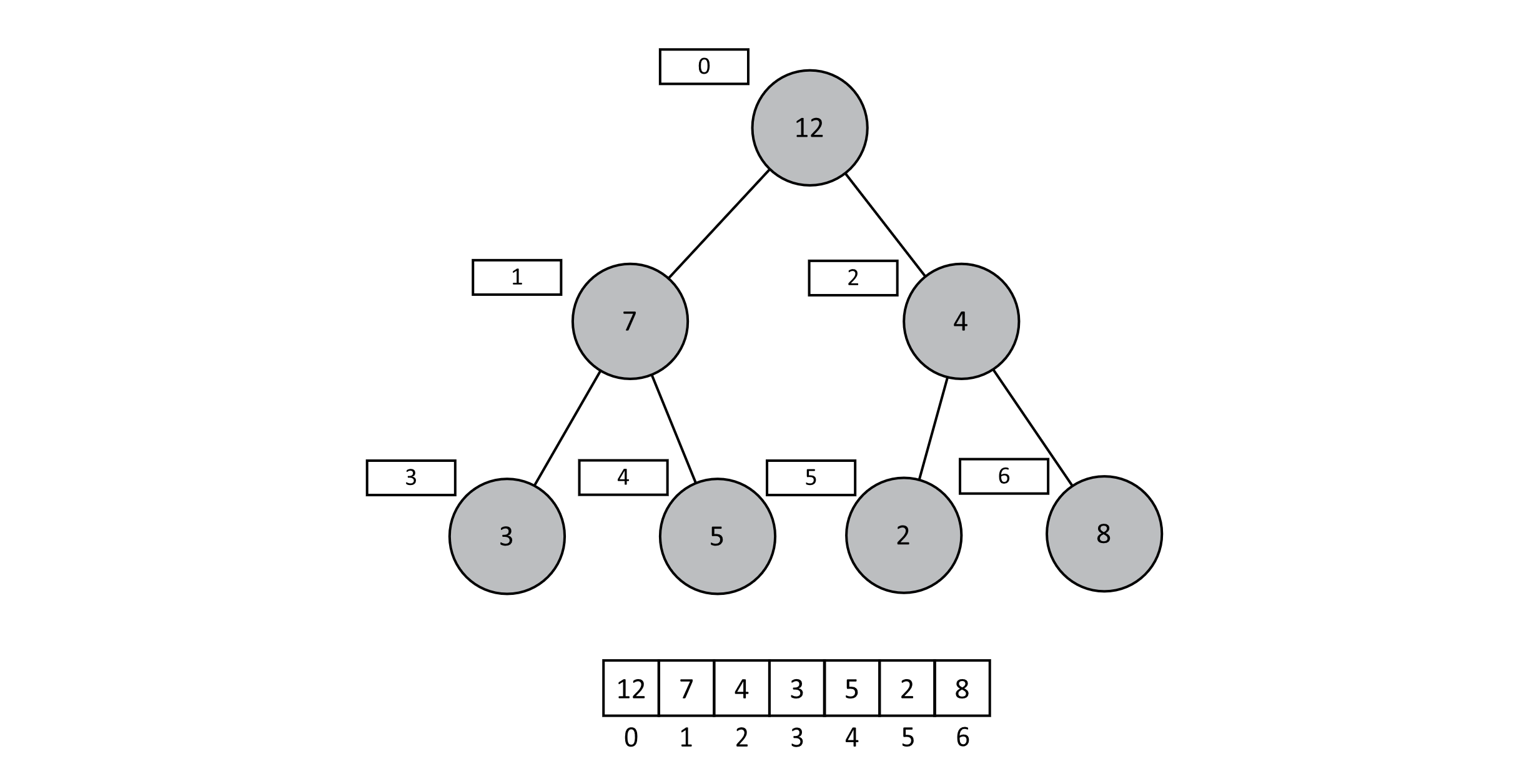
Figure 9.3
What can we now claim about the state of our binary heap? Subheaps starting at indexes 1, 3, 4, and 5 are all still valid subheaps because the heap property is preserved. In other words, our erroneous insertion of 8 under 4 does not alter the descendants of these 4 nodes. As a result, we could hypothetically leave these subheaps unaltered in our corrected heap. This leaves nodes at indexes 0 and 2. These are the two nodes that have had their descendants altered. The heap property between node indexes 2 and 6 no longer holds, so let us start there. If we were to switch the 4 and 8, we would restore the heap property between those two indexes. We also know that moving 8 into index 2 will not affect the heap property between indexes 2 and 5. If 2 was less than 4 and 4 was found to be less than 8, switching the 4 and 8 does not impact the heap property between indexes 2 and 5. Once the 4 and 8 are in the correct positions, we know that the subheap starting at index 2 is correct. From here, we simply perform the same operations on subsequent parents until the next parent’s value is greater than the value we are trying to insert. Given that we are inserting 8 and our root node’s value is 12, we can stop iterating at this point. The pseudocode below is descriptive but much simpler than practical implementations, which must consider precise data structures for storing the heap. This provides the general pattern for inserting into a binary heap regardless of the underlying implementation. We place the new element at the end of the heap and then essentially siftUp that element to the place that will preserve the heap property.

Runtime of insertion is independent of whether the heap is stored as object references or an array. In either case, we have to compare n.value to n.parent.value at most O(log n) times. Note that, unlike the caveat included in binary search trees (where traversing an unbalanced tree may be as slow as O(n)), binary heaps maintain their balance by building each new depth level before increasing its depth. This ensures that an imbalanced binary heap does not occur. This fact guarantees that our insert operation is O(log n).
A specific implementation for insert with our array-based heap is provided below:

Extraction
Extraction is the process of removing the root node of a binary heap. It works much the same way as insertion but in reverse. The general strategy is as follows.
To extract an element from the heap…
- Extract the root element, and prepare to return it.
- Replace the root with the last element in the heap.
- Call heapify on the new root to correct any violations of the heap property.
As an example, consider our corrected heap from before. If we overwrite our 12 (at index 0) with the last value from the array (4 at index 6), the result will be as follows in figure 9.5. Just as we saw with insertion, many of our subheaps still have the heap property preserved. In fact, the only two places where the heap property no longer holds are from indexes 0 to 1 and 0 to 2. If the value at the root is less than the maximum value of its two children, then we swap the root value and that maximum. We will continue this process of pushing the root value down until the current node is greater than both children, thus conforming to the heap property. In this case, we swap the 4 with the 8. The root node conforms to the heap property because its children are 7 and 4. The node with value 4 (now at index 2) only has one child (2 at index 5). It conforms to the heap property, and our extraction is complete.
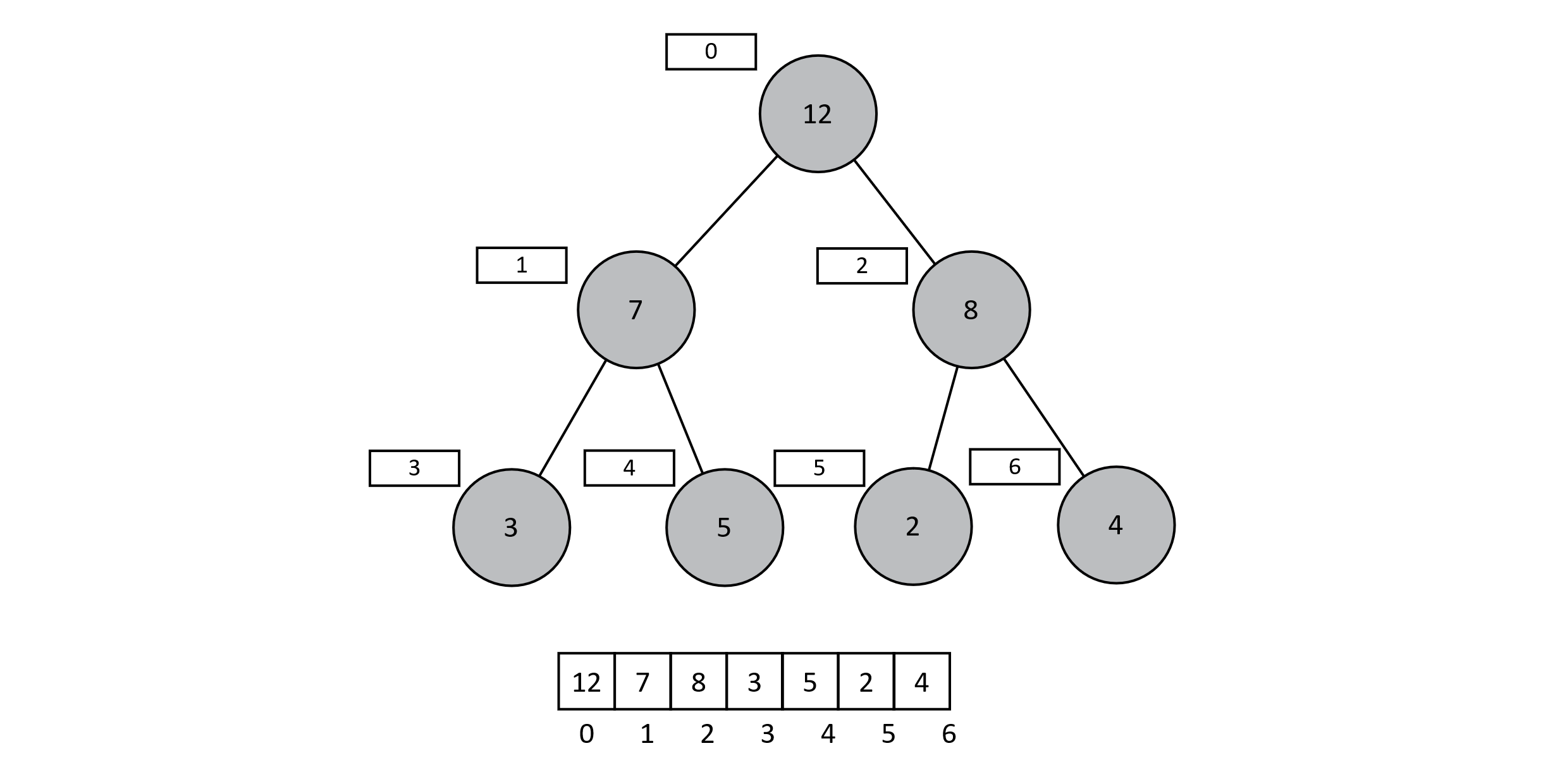
Figure 9.4
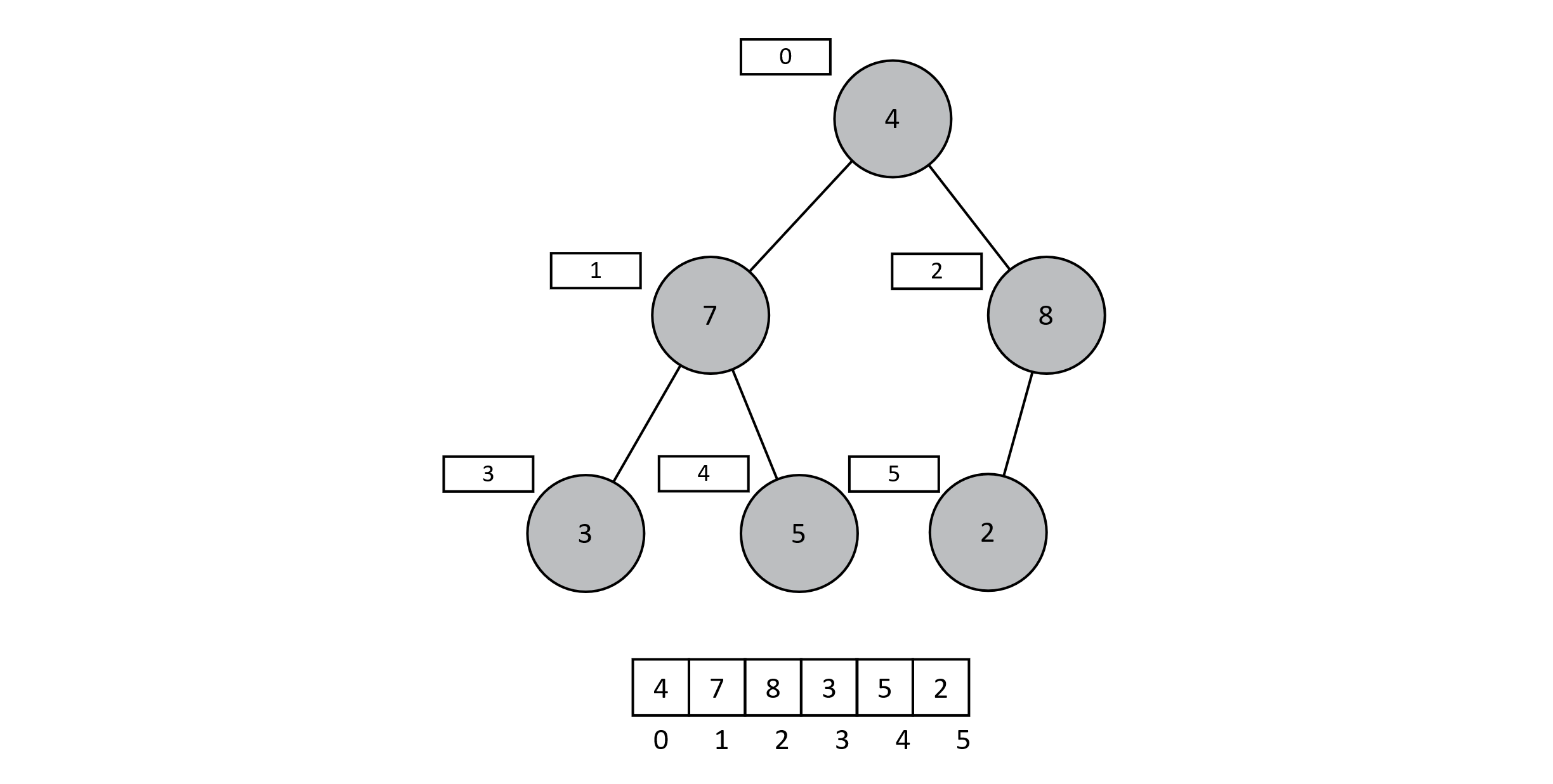
Figure 9.5
As before, the pseudocode is much simpler than the actual implementation.

The array-based implementation could use the heapify function to give the following code:

While accessing the max-element would only require O(1) time, updating the heap after it is removed requires a call to heapify. This function requires O(log n). While not constant time, O(log n) is a great improvement over our initial naïve implementation ideas from the introduction. Our initial idea of sorting and then always copying moving elements up or down would have required O(n) operations to maintain our priority queue when inserting and removing elements. The max-heap greatly improves on these complexity estimates, giving O(log n) for both insert and extract.
Heap Sort
Heap Sort presents an interesting use of a priority queue. It can be used to sort the elements of an array. Once insertion and extraction have been defined, Heap Sort becomes a trivial step. We first build the heap, then repeatedly extract the maximum element and put it at the end of the array. Much like Selection Sort, Heap Sort will find the extreme value, place it into the correct position, then find the extreme of the remaining values. The trick is in how we perceive the heap. If we model it using an array, we can then sort the values in place by extracting the maximum. The extraction makes the heap smaller by one, but arrays are fixed size and still have the extra space allocated at the end. This portion at the end of the array becomes our sorted portion. As we perform more extractions and move those extracted values to the end of the array, our sorted portion gets bigger. See the figure below for an example. Unlike Selection Sort, where finding that extreme value requires an O(n) findMax or findMin, heaps allow us to extract the extreme value and revise our heap in O(log n) time. We perform this operation O(n) times, resulting in an O(n log n) sorting algorithm. The following figure gives an example execution of the sorting algorithm:
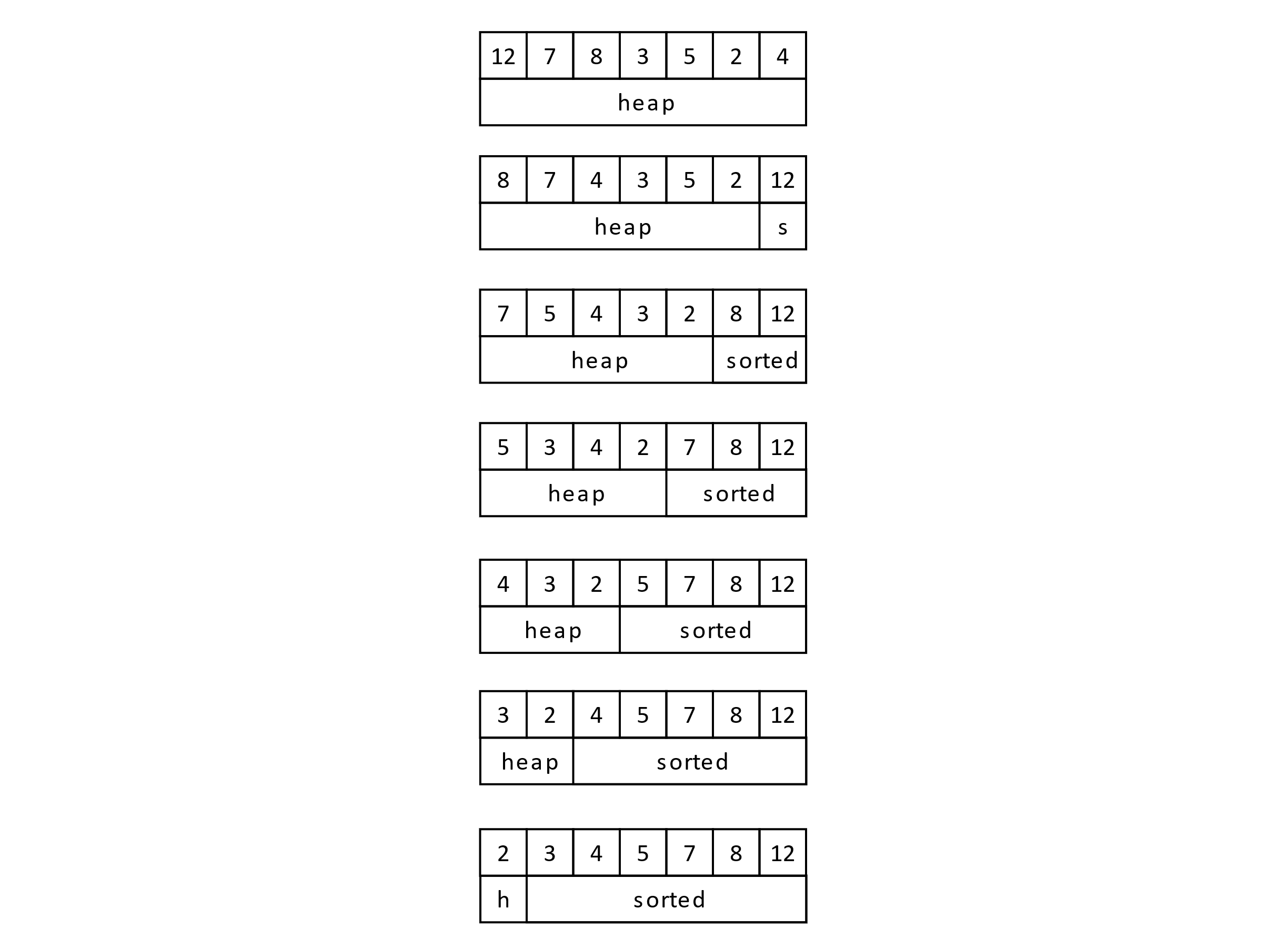
Figure 9.6
Before we give the implementation of Heap Sort, we should also mention how to build the heap in the first place. If we are given an array of random values, there is no guarantee that these will conform to our requirements of a heap. This is accomplished by calling the heapify function repeatedly to build valid heaps starting at the deeper levels of the balanced tree up to the root. Below is the code for buildHeap, which will take an array of elements to be sorted and put them into the correct heap ordering:
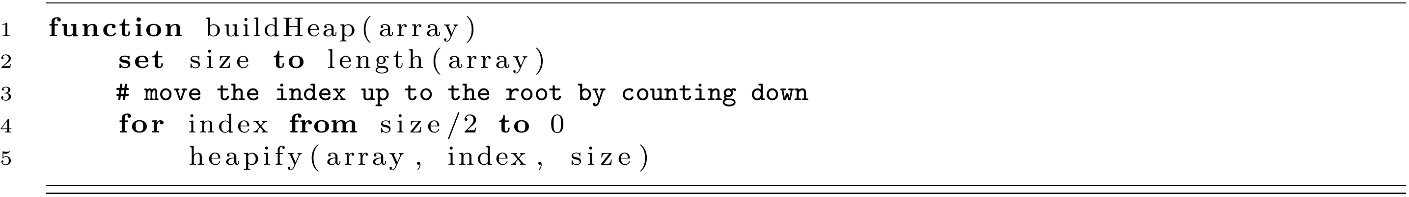
It might be unintuitive, but buildHeap is O(n) in its time complexity. At first glance, we see heapify, an O(log n) operation, getting called inside a loop that runs from size/2 down to 0. This might seem like O(n log n). What we need to remember though is that O(log n) is a worst-case scenario for heapify. It may be more efficient. As we build the heap up, we start at position size/2. This is because half of the heap’s elements will be leaves of the binary tree located at the deepest level. As we heapify the level just before the leaves, we only need to consider three elements: the parent and its two leaf children. As heapify runs, the amount of work is proportional to the height of the subtree it is operating on. Only on the very last call does heapify potentially visit all log n of the levels of the tree. We will omit the calculation details, but it has been proven that O(n) gives a tighter bound on the worst-case time complexity of buildHeap.
Now we are ready to implement Heap Sort. An implementation is provided below. Our O(n log n) complexity comes from calling heapify from the root every time we extract the next largest value. Another useful feature of this algorithm is that it is an in-place sorting algorithm. This means the extra space (auxiliary space) only consumes O(1) space in memory. So Heap Sort compares favorably to Quick Sort with a better worst-case complexity (O(n log n) vs. O(n2)), and it offers an improvement over Merge Sort in terms of its auxiliary space usage (O(1) auxiliary space vs. O(n)). We should note that Heap Sort may perform poorly in practice due to cache misses, since traversing a tree skips around the elements of the array.

This section has provided an overview of heapSort and the concept of a heap more generally. Heaps are great data structures for implementing priority queues. They can be implemented using arrays or linked data structures. The array implementation also demonstrates an interesting example of embedding a tree structure into a linear array. The power and simplicity of heaps make them a popular data structure. One potential disadvantage of the heap is that merging two heaps might require O(n) operation. To combine these two heaps, we would need to create a new array, recopy the elements, and then call buildHeap, taking O(n) operations. In the next section, we will discuss a new data structure that supports an O(log n) union operation.
Binomial Heaps
The binomial heap supports a fast union operation. When two heaps are given, union can combine them into a new heap containing all the combined elements from the two heaps. Binomial heaps are linked data structures, but they are a bit more complex than linked lists or binary trees. There is an interesting characteristic to their structure, which models the pattern of binary numbers, and combining them parallels binary addition. Binary numbers and powers of 2 seem to pop up everywhere in computer science. In this section, we will present the binomial heap and demonstrate how it can provide a fast union operation. Then we will see how many of the other operations on heaps can be implemented with clever use of the union function.
Linked Structures of Binomial Heaps
To build our heap, we need to discuss two main structures. The first part is the binomial tree. Each binomial tree is composed of connected binomial nodes. The structure of a binomial tree can be described recursively. Each binomial tree has a value k that represents its degree. The degree 0 tree, B0, has one element and no children. A degree k tree, Bk, has k direct children but 2k nodes in total. When the Bk tree is constructed, the roots of two Bk−1 trees are examined. The largest root of the two trees is assigned as the root of the new tree, assuming a max-binomial-heap. The heap is then represented as a list of binomial trees. A collection of trees is known as a forest. The main idea of the binomial is that each heap is a list of trees, and to combine the two heaps, one just needs to combine all the trees of equal degree. To facilitate this, the trees are always ordered by increasing tree degrees. A few illustrations will help you understand this process a little better.
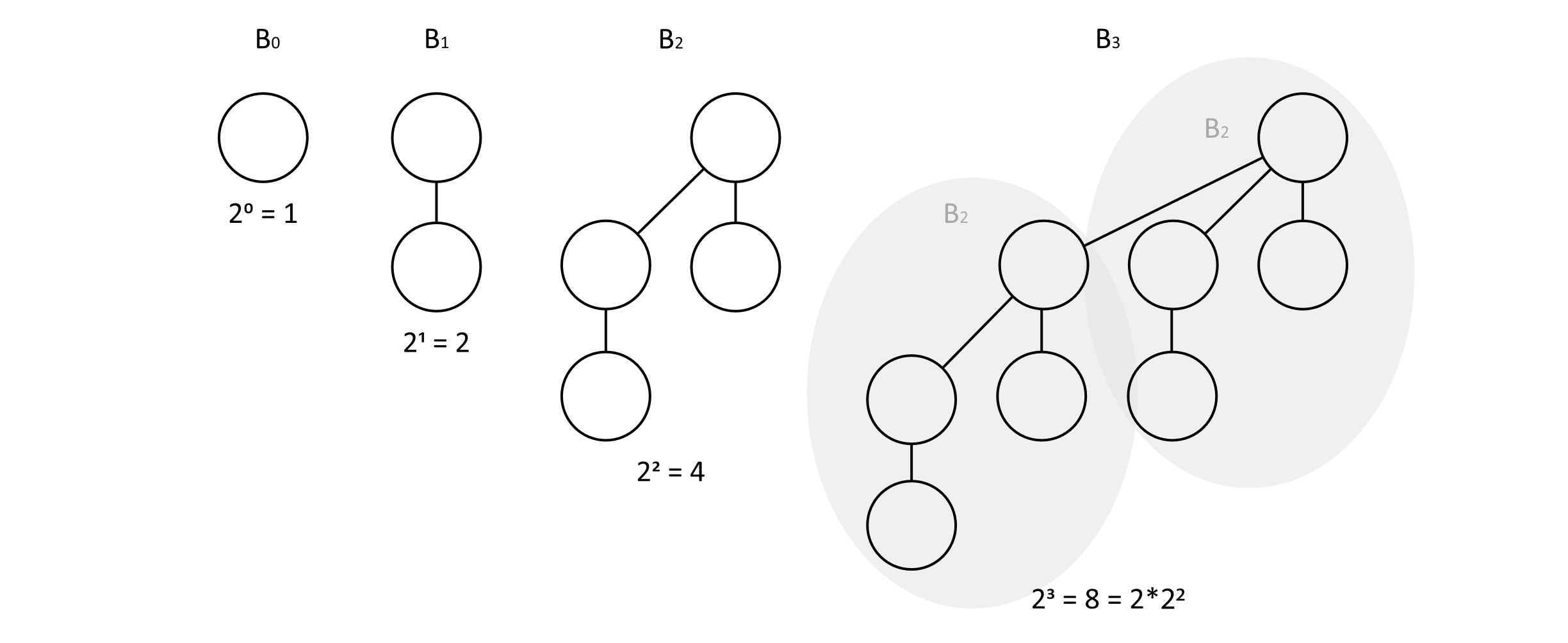
Figure 9.7
Using these trees, a heap would then be a list of these trees. To preserve the max-heap property, any node’s priority must be larger than its child. Below is an example binomial heap. Let’s call this heapA:
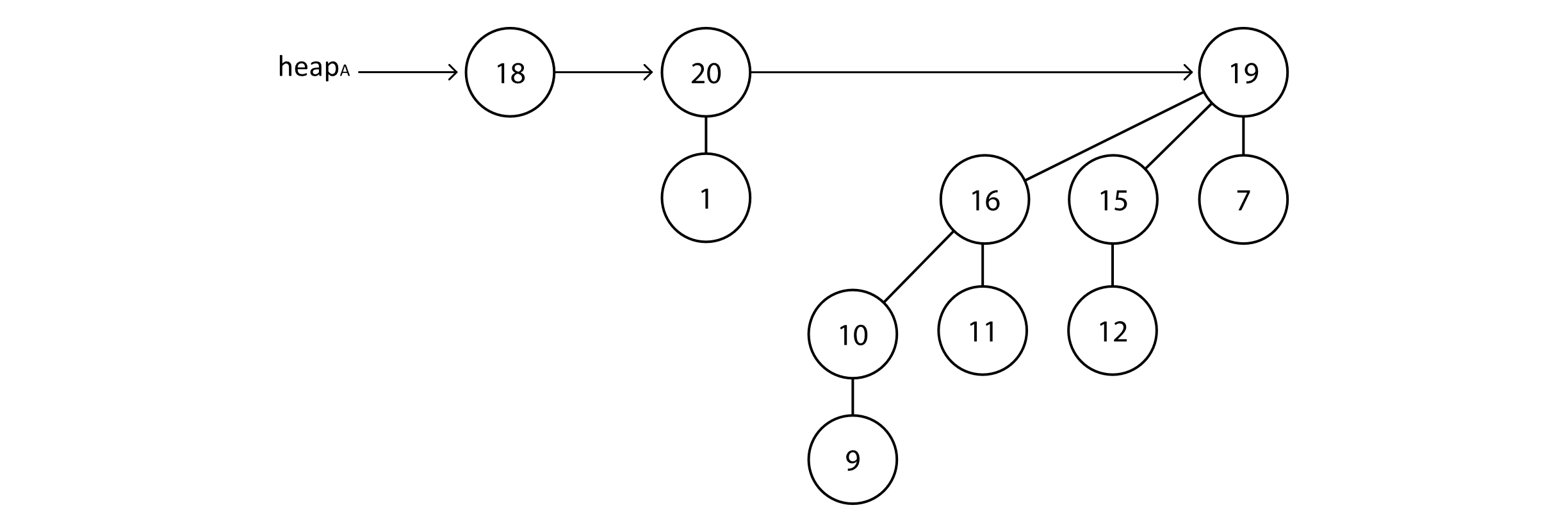
Figure 9.8
Notice that the maximum element is in B1 tree of this heap. This illustrates that the actual max-heap element is one of the root nodes of trees in the list. Now we can make the connection to binary numbers. This heap will either have a tree of any given degree or not. This could be indicated by a 0 or 1. So the above heap has a degree 0 tree, a degree 1 tree, and a degree 3 tree. In binary with the bits correctly ordered, this would be 10112 or the number 1110 in base 10. Suppose there is another heap, heapB, that we wish to merge with. This is given below:
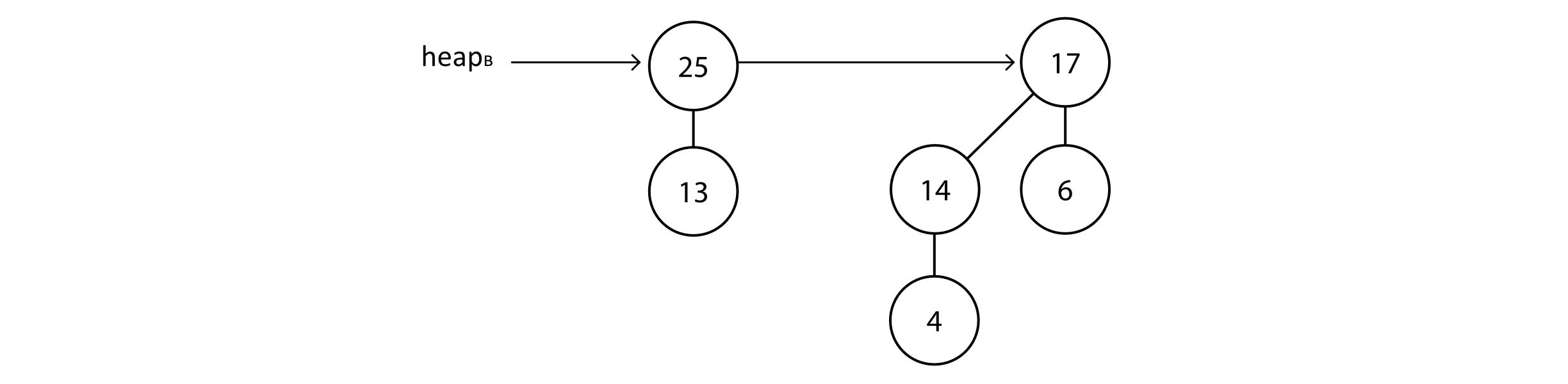
Figure 9.9
This heap has trees for degrees 1 and 2. In binary, we could represent this pattern as 1102 or the number 610 in base 10. We will soon look at how these heaps could be merged, but first let’s consider the process of binary addition for these two binary numbers: 11 and 6. The figure below gives an example of the addition:
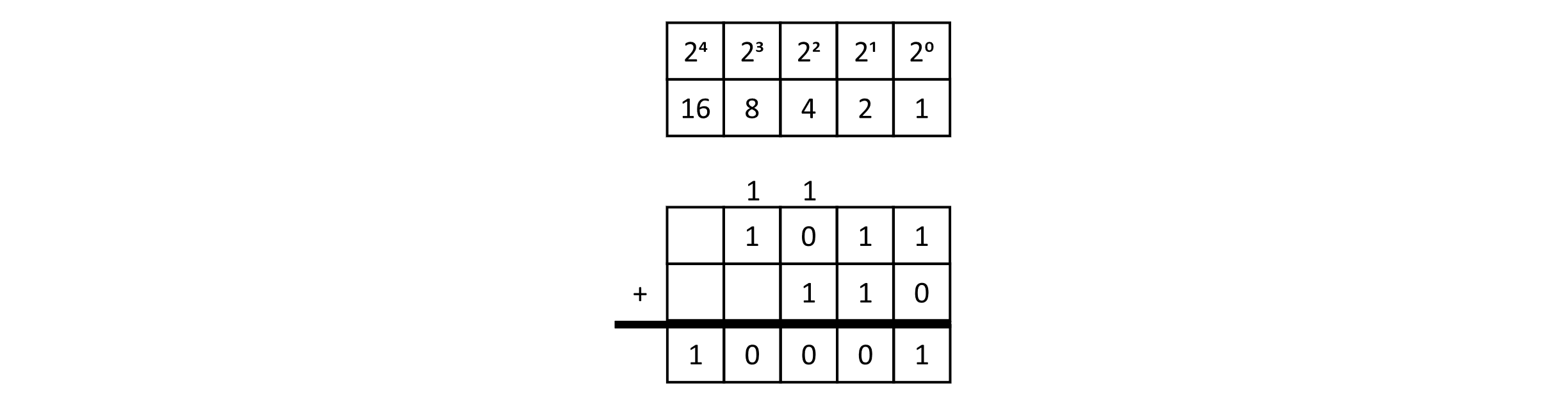
Figure 9.10
This diagram of binary addition also demonstrates how our trees need to be combined to create the correct structure for our unified trees. The following images will show these steps in action. First, we will merge the two lists into another list (but not a heap yet). This merge is similar to the merge operation in Merge Sort:
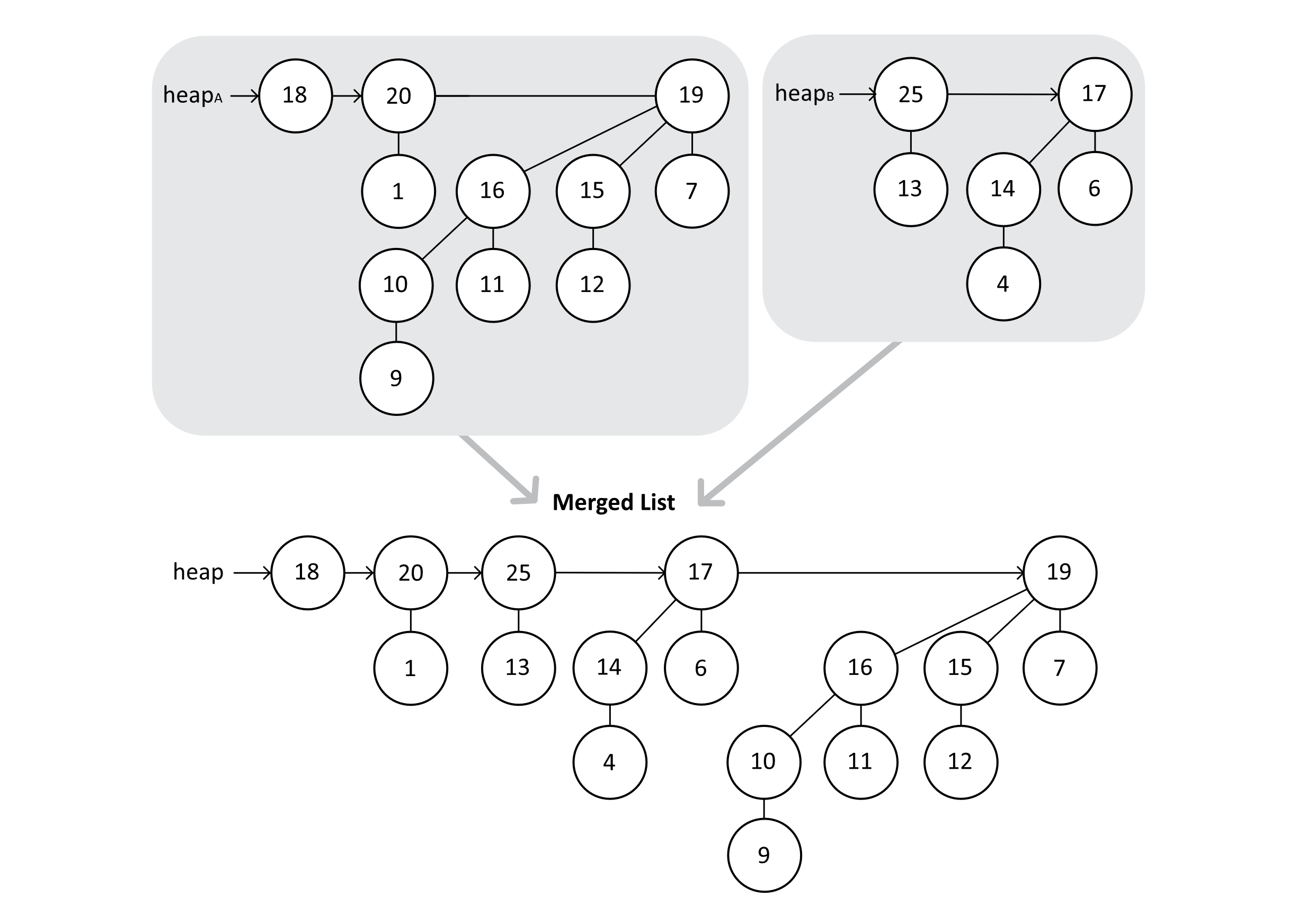
Figure 9.11
Next, the algorithm will examine two trees at a time to determine if the trees are the same degree. Any trees that have an equal degree will be merged. Because the nodes are ordered by degree, we only need to consider two nodes at a time and potentially keep track of a carry node.
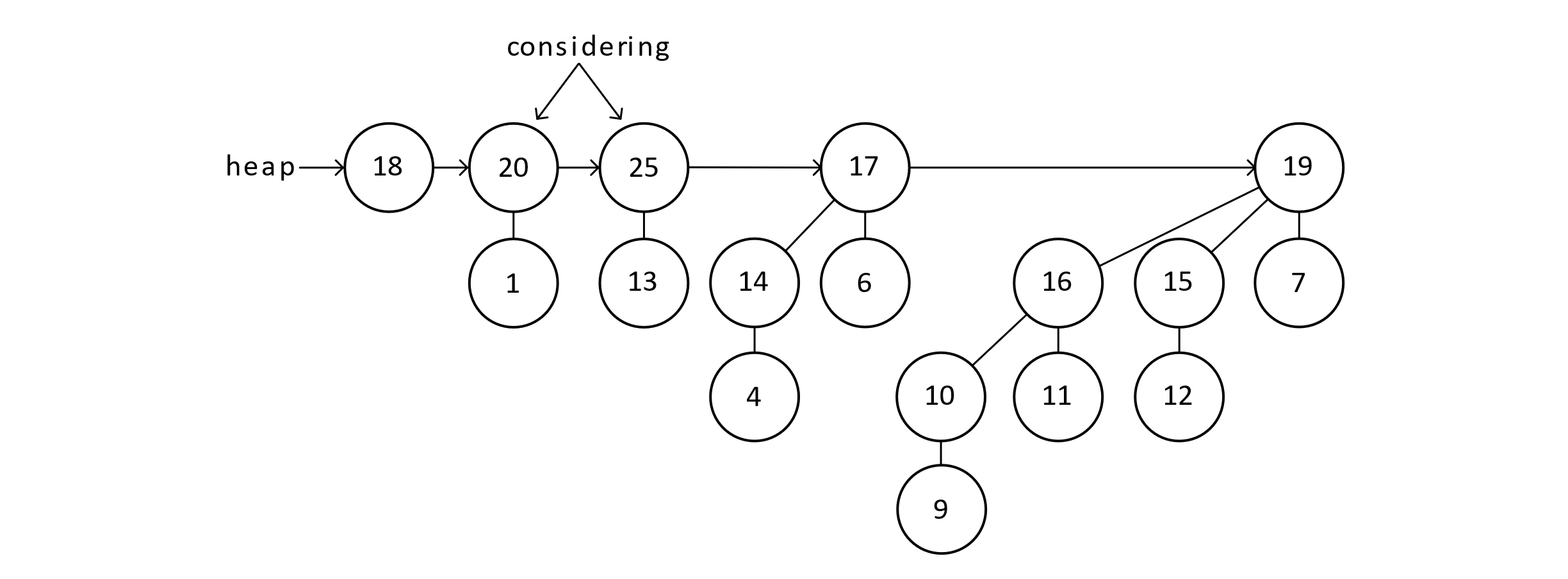
Figure 9.12
These nodes are not equal in degree. We can move on.
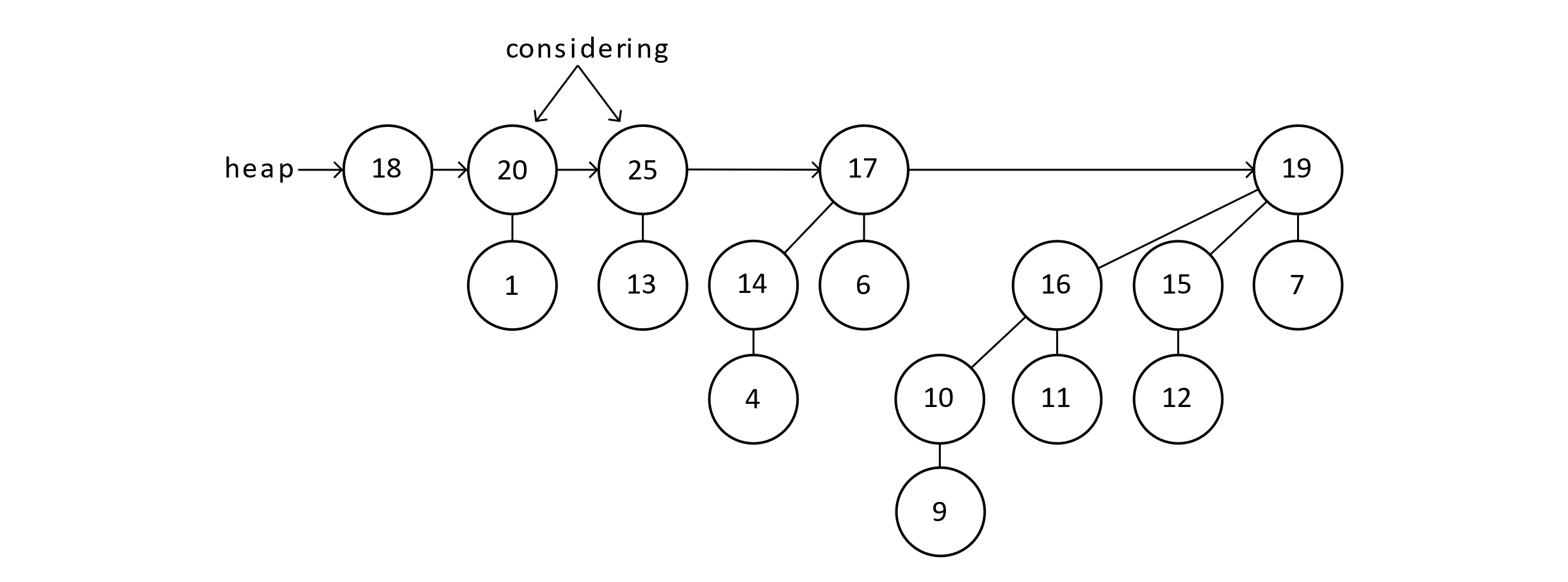
Figure 9.13
Now we are considering two nodes of equal degree. These two B1 trees need to become a B2 tree.
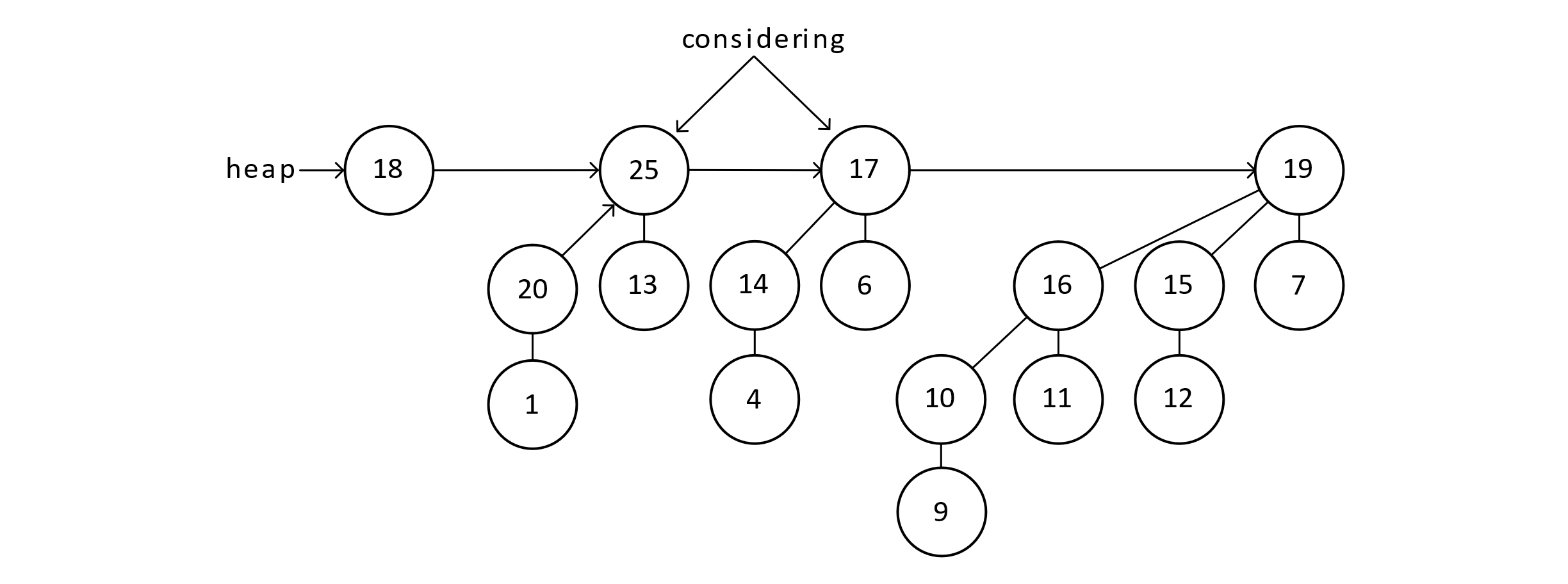
Figure 9.14
After combining the B1 trees, we now have two B2 trees that need to be combined. This will be done such that the maximum item of the roots becomes the new root.
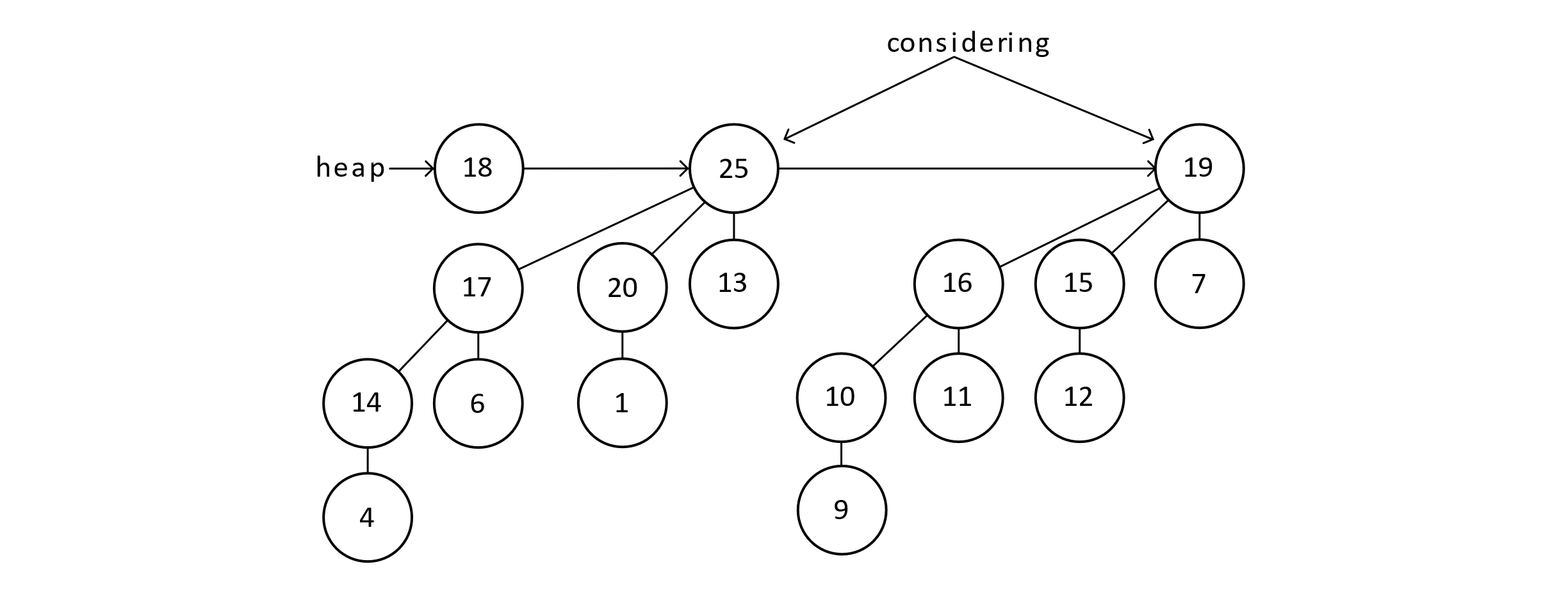
Figure 9.15
Again, the “carry” from addition means that we now have two B3 trees to merge. This step creates a B4 tree with 24 = 16 nodes. The final merged heap is below, with one B0 node and one B4 node:
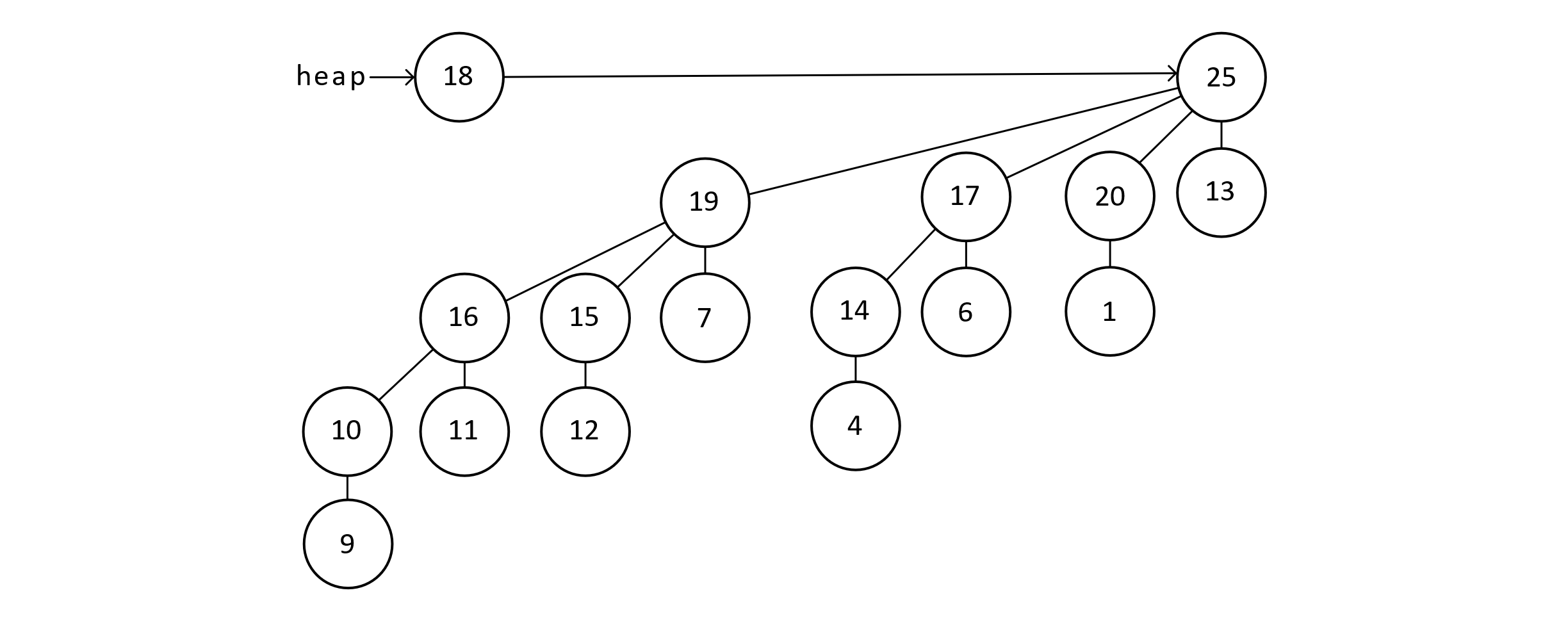
Figure 9.16
Implementing Binomial Trees
To implement Binomial trees, we will need to create a node class with appropriate links. Again, we will use references, also known as pointers, for our links. A node—and by extension, a tree—can be represented with the BinomialTree class below. In this class, Data would be any entity that needed storing in the priority queue:

For the BinomialHeap itself, we only need a reference to the first tree in the forest. This simple pseudocode is presented below:

As we progress toward a complete implementation, we will build up the operation that we need, working toward the union operation. Once union is implemented, adding or removing items from the heap can be implemented through the clever usage of union. For now, let’s implement the combine and merge functions.
Combining Two Binomial Trees
The combine function is given below. This simple function combines two Bk−1 trees to create a new Bk tree. This function will make the first tree a child of the second tree. We will assume that tree1.priority is always less than or equal to tree2.priority.
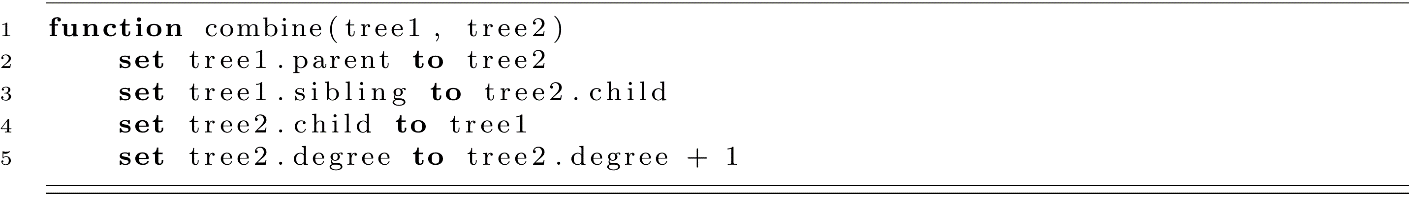
The figure below shows how two B2 trees would be combined to form a B3 tree. This figure also identifies the parent, sibling, and child links for each node. Links that do not connect to any other node have the value null. This figure can help you understand the combine function. We need to maintain these links in a specific way to make the other operations function correctly. Notice that the children of the root are all linked together by sibling links, like a linked list’s next reference.
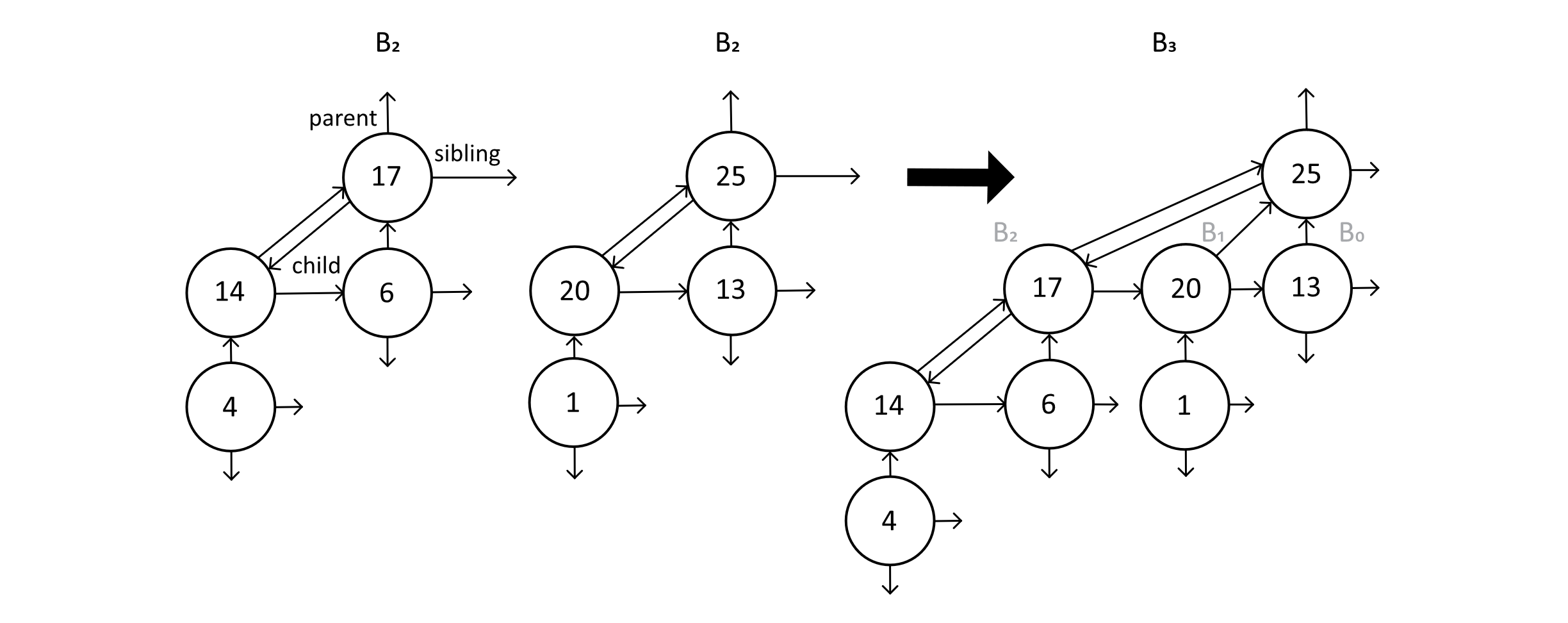
Figure 9.17
Another interesting feature of binomial trees is that each tree of degree k contains subtrees of all the degrees below it. These are the children linked from the first child of the new tree. For example, the B3 tree contains a B0, B1, and B2 subtree in descending order. You can observe these in the figure above. This fact will come in handy when we implement the extract function for binomial heaps.
Merging Heaps
Now that we can combine two trees to form a higher-degree tree, we should implement the mergeHeaps function. This will take both heaps and their forests of binomial trees and merge them. You can think of these “forests” as linked lists of binomial trees. Once these forests are merged, trees of equal degree will be adjacent in the list. This sets the stage for our “binary addition” algorithm that will calculate the union of both heaps. The code for mergeHeaps is below:

This may look a little difficult to follow, but the concept is simple. Starting with links to the lists of binomial trees, we first check to see if any of these are null. If so, we just return the other one. Afterward, we check which of the nonnull trees has the lowest degree and set our newHeap’s head to this tree. The while-loop then appends the tree with the next smallest degree to the growing list. The loop continues until one of the two lists of trees reaches its end. After that, the remaining trees are linked to the list by the current reference, and the head of our merged list is returned. Notice that the sibling references serve the same role as the next pointers of a linked list.
The Binomial Heap Union Operation
Now we will tackle the union function. This function performs the final step of combining two binomial heaps by traversing the merged list and combining any pairs of trees that have equal degrees. The algorithm is given below:

The union function begins by setting up a new, empty heap and then merging the two input heaps. Once the merged list of trees is generated, the algorithm traverses the list using three references (previousTree, currentTree, and nextTree). The code will advance the traversal forward if currentTree and nextTree have different degree values. Another case that moves the traversal forward is when nextTree.sibling has the same degree as currentTree and nextTree. This is because nextTree and nextTree.sibling will need to combine to occupy the k + 1 degree level. When a call to combine is needed, the algorithm checks which tree has the highest priority, and that tree’s root becomes the root of the k + 1 tree.
Time Complexity of Union
The union operation is completed, but now we should analyze its complexity. One of the main reasons for choosing a binomial heap was its fast union operation. How fast is it though? We will be interested in the time complexity of union. The algorithm traverses both heaps for the merge and the sequence combinations. This means that the complexity is proportional to the number of trees. We need to determine how many binomial trees are needed to represent all n elements of the priority queue. Recall that there are many parallels between binomial heaps and binary numbers. If we have 3 items in our heap, we need a tree of degree 0 with 1 item and a tree of degree 1, with 2 items. To store 5 items, we would need a degree 0 tree with 1 item, and a degree 2 tree with 4 items. Here we see that the binary representation of n indicates which trees of any given degree are needed to store those elements. A number can be represented in binary using a maximum number of bits proportional to the log of that number. So there are log n trees in a binomial heap with n elements. This means that the time complexity of union is bounded by O(log n). By similar reasoning, the time cost for finding the element with the highest priority is O(log n), the number of binomial trees in the heap.
Inserting into a Binomial Heap
With union completed, we can see the benefit of this operation. Below is an implementation of insert using union. The union operation takes O(log n) time, and all other operations can be performed in O(1) time. This makes the time complexity for insert O(log n).

Extracting the Max-Priority Element
The priority queue would not be complete without a function to extract the maximum element from the heap. The extract function takes a bit more work, but ultimately extract executes in O(log n) time. The maximum priority element must be the root of one of the heap’s trees. This function will find the maximum priority element and remove its entire tree from the heap’s tree list. Next, the children of the max-element are inserted into another heap. With the two valid heaps, we can now call union to create the binomial heap that results from removing the highest priority element. This element can be returned, and the binomial heap will have been updated to reflect its new state. We note that in this implementation, there is a side effect of extract. This function returns the maximum priority element and removes it from the input heap as a side effect that modifies the input. Another approach would be to implement an accessMax function to find the maximum priority element and return it without updating the heap. This means that extracting the element would require a call to accessMax to save the element, and then extract would be called. We could also consider extracting part of the BinomialHeap class and avoid passing any heap as input.

Increase-Priority and Delete Operations
We will continue our theme of building new operations by combining old ones. Here we will present the delete operation. This operation will make use of extract and increasePriority, which we will develop next. Creating the increasePriority function will rely on the parent points that we have been maintaining. When the priority of an element is increased, it may need to work its way up the tree structure toward the root. The following code gives an implementation of increasePriority. We assume for simplicity that we already have a link to the element whose priority we want to increase. The element with the highest priority moves up the tree just like in the binary heap’s siftUp operation.

Now we can implement delete very easily using the MAX special value. We increase the element’s priority to the maximum possible value and then call extract. An implementation of delete is provided below. Again, we assume that a link to the element we wish to delete is provided.
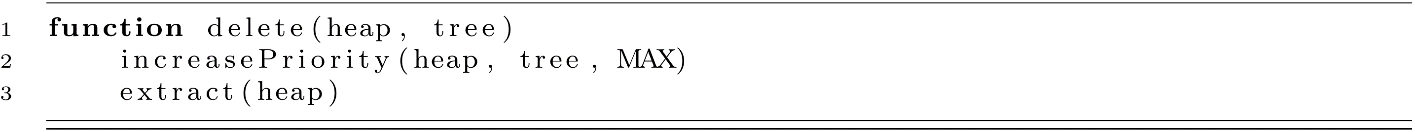
The time complexity of delete is derived from the complexity of increasePriority and extract. Each of these requires O(log n) time.
A Note on the Name
Before we close this chapter on priority queues, we should discuss why these are called binomial heaps. The name “binomial heap” comes from a property that for a binomial tree of degree k, the number of nodes at a given depth d is k choose d. This is written as ![]()
Summary
In this chapter, we explored one of the most important abstract data types: the priority queue. This data structure provides a collection that supports efficient insert and remove operations with the added benefit of removing elements in order of priority. We looked at two important implementations. One implementation used an array and created a binary heap. We also saw that this structure can be used to implement an in-place O(n log n) sorting algorithm by simply extracting elements from the queue and placing them in the sorted zone of the array. Next, we explored the binomial heap’s implementation. This data structure provides an O(log n) union operation. Though the implementation of binomial heaps seems complex, there is an interesting and beautiful simplicity to its structure. Our union algorithm also draws parallels to the addition of binary numbers, making it an interesting data structure to study. Any student of computer science should understand the concept of priority queues. They form the foundation of some interesting algorithms. For example, chapter 11 on graphs will present an algorithm for a minimum spanning tree that relies on an efficient priority queue. The minimum spanning tree is the backbone of countless interesting and useful algorithms. Hopefully, by now, you are beginning to see how data structures and algorithms build on each other through composition.
Exercises
- Implement Heap Sort on arrays in the language of your choice. Revisit your work from chapter 3 on sorting. Using your testing framework, compare Heap Sort, Merge Sort, and Quick Sort. Which seems to perform better on average in terms of speed? Why would this be the case on your machine?
- What advantages would Heap Sort have over Quick Sort? What advantages would Heap Sort have over Merge Sort?
- Extend your heap implementation to use references to data records with a priority variable rather than just an integer as the priority.
- Implement both binomial heaps using linked structures and binary heaps using an array implementation. Using a random number generator, create two equal-sized heaps, and try to merge them. Try the merge with binomial heaps, and get some statistics for the merge speed. Compare with the merge speed of binary heaps with integers. Repeat this process several times to explore how larger n affects the speed of the rival heap merge algorithms. The results may not be what you expect. How might caches play a role in the speed of these algorithms?
References
Cormen, Thomas H., Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, 2nd ed. Cambridge, MA: The MIT Press, 2001.
Vuillemin, Jean. “A Data Structure for Manipulating Priority Queues.” Communications of the ACM 21, no. 4 (1978): 309–315.
