
10 Dynamic Programming
Learning Objectives
After reading this chapter you will…
- understand the relationship between recursion and dynamic programming.
- understand the benefits of dynamic programming for optimization.
- understand the criteria for applying dynamic programming.
- be able to implement two classic dynamic programming algorithms.
Introduction
Dynamic programming is a technique for helping improve the runtime of certain optimization problems. It works by breaking a problem into several subproblems and using a record-keeping system to avoid redundant work. This approach is called “dynamic programming” for historical reasons. Richard Bellman developed the method in the 1940s and needed a catchy name to describe the mathematical work he was doing to optimize decision processes. The name stuck and, perhaps, leads to some confusion. This is because many terms in computer science have several meanings depending on the context, especially the terms “dynamic” and “programming.” In any case, the technique of dynamic programming remains a powerful tool for optimization. Let’s look deeper into this concept by exploring its link to problems that can be expressed recursively.
Recursion and Dynamic Programming
Recursive algorithms solve problems by breaking them into smaller subproblems and then combining them. Solving the subproblems is done by applying the same recursive algorithm to the smaller subproblems by breaking the subproblems into sub-subproblems. This continues until the base case is reached. Below is a recursive algorithm from chapter 2 for calculating the Fibonacci numbers:

To solve the problem for fibonacci(n), we need to solve it for fibonacci(n − 1) and fibonacci(n − 2). We see that there are subproblems with the same structure as the original problem.
The Fibonacci numbers algorithm is not an optimization problem, but it can give us some insight to help understand how dynamic programming can help us. Let’s look at a specific instance of this problem. The recursive formula for Fibonacci numbers is given below:
F0 = 0
F1 = 1
Fn = Fn−1 + Fn−2.
Now let’s explore calculating the eighth Fibonacci number:
F8=F8−1 + F8−2
=F7 + F6
=(F7−1 + F7−2) + (F6−1 + F6−2)
=(F6 + F5) + (F5 + F4)
=((F6−1 + F6−2) + (F5−1 + F5−2)) + ((F5−1 + F5−2) + (F4−1 + F4−2))
=((F5 + F4) + (F4 + F3)) + ((F4 + F3) + (F3 + F2))
…and so on.
There are two key thoughts we can learn from this expansion for calculating F8. The first thought is that things are getting out of hand and fast! Every term expands into two terms. This leads to eight rounds of doubling. Our complexity looks like O(2n), which should be scary. Already at n = 20, 220 is in the millions, and it only gets worse from there. The second thought that comes to mind in observing this explanation is that many of these terms are repeated. Let’s look at the last line again.

Figure 10.1
Already, we see that F4 and F3 are used three times each, and they would also be used in the expansion of F5 and F4. If we could calculate each of these just once and reuse the value, a lot of computation could be saved. This is the big idea of dynamic programming.
In dynamic programming, a record-keeping system is employed to avoid recalculating subproblems that have already been solved. This means that for dynamic programming to be helpful, subproblems must share sub-subproblems. In these cases, the subproblems are not independent of one another. There are some repeated identical structures shared by multiple subproblems. Not all recursive algorithms satisfy this property. For example, sorting one-half of an array with Merge Sort does not help you sort the other half. With Merge Sort, each part is independent of the other. In the case of Fibonacci, F7 and F6 both share a need to calculate F1 through F5. Storing these values for reuse will greatly improve our calculation time.
Requirements for Applying Dynamic Programming
There are two main requirements for applying dynamic programming. First, a problem must exhibit the property known as optimal substructure. This means that an optimal solution to the problem is constructed from optimal solutions to the subproblems. We will see an example of this soon. The second property is called overlapping subproblems. This means that subproblems are shared. We saw this in our Fibonacci example.
Optimal Matrix Chain Multiplication
A classic application of dynamic programming concerns the optimal multiplication order for matrices. Consider the sequence of matrices {M1, M2, M3, M4}. There are several ways to multiply these together. These ways correspond to the number of distinct ways to parenthesize the matrix multiplication order. For the mathematically curious, the Catalan numbers give the total number of possible ways. For example, one way to group these would be (M1 M2) (M3 M4). Another way could be M1 ((M2 M3) M4). Any grouping leads to the same final result, but the number of multiply operations of the overall calculation could differ greatly with different groupings. To understand this idea, let’s review matrix multiplication.
Matrix Multiplication Review
Matrix multiplication is an operation that multiplies and adds the rows of one matrix with the columns of another matrix. Below is an example:
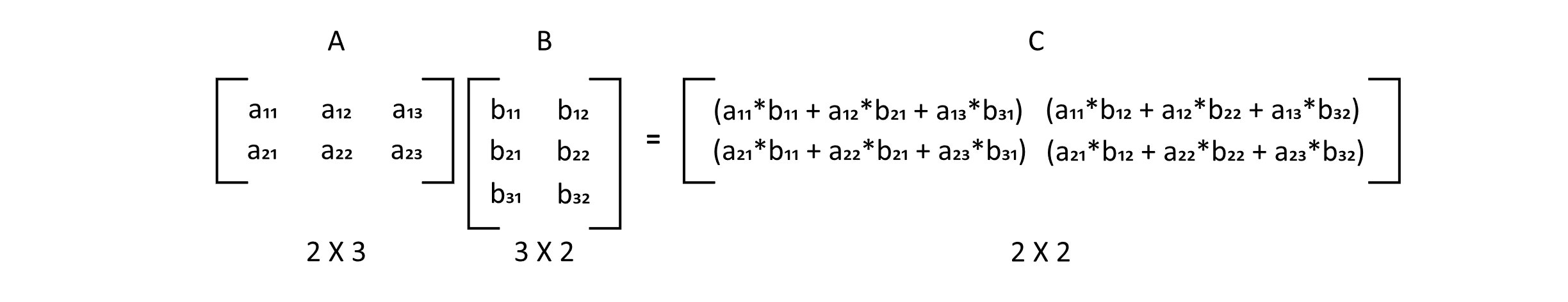
Figure 10.2
Here we have the matrix A and the matrix B. A is a 2-by-3 matrix (2 rows and 3 columns), and B is a 3-by-2 matrix (3 rows and 2 columns). The multiplication of AB is compatible, which means the number of columns of A is equal to the number of rows in the second matrix, B. When two compatible matrices are multiplied, their result has a structure where the number of rows equals the number of rows in the first matrix and the number of columns equals the number of columns in the second matrix. The process is the same for compatible matrices of any size.
Implementing Matrix Multiplication
Now let’s consider an algorithm for matrix multiplication. To simplify things, let’s assume we have a Matrix class or data structure that has a two-dimensional (2D) array. Another way to think of a 2D array is as an array of arrays. We could also think of this as a table with rows and columns. The structure below gives a general example of a Matrix class. Within this class, we also have two convenience functions to access and set the values of the matrix based on the row and column of the 2D array.

With this structure for a Matrix class, we can implement a matrix multiplication procedure. Below we show the process of performing matrix multiplication on two compatible matrices:

This function implements the matrix multiplication procedure described above. On line 12, the new value of the (i, j) entry in the result matrix is calculated. We see that this involves a multiply operation and an addition operation. On a typical processor, the multiply operation is slower than addition. As we think about the complexity of matrix multiplication, we will mainly consider the number of multiplications. This is because as the matrices get large, the cost associated with multiplication will dominate the cost of addition. For this reason, we only consider the number of multiplications.
So how many multiplications are needed for matrix multiplication? The pattern above has a triple-nested loop. This gives us a clue to the number of times the inner code will run. As a result, we can expect the number of multiplications to be equal to the number of times the inner code will run. Let’s assume that matrix A has ra rows and ca columns, and that matrix B, in a similar way, has rb rows and cb columns. For A and B to be compatible matrices, the value of ca would have to be equal to rb. We know that the inner loop with index k runs a total of ca times. This entire loop is executed once for every cb of B’s columns (cb * ca). Finally, these two inner loops for j and k would all run for every row in A, leading to multiplications proportional to ra * ca * cb. This illustrates that as the size of the matrices gets larger, the number of multiplications grows quickly.
Why Order Matters
Now that we have seen how to multiply matrices together and understand the computational cost, let’s consider just why choosing to multiply in a specific order is important. Suppose that we need to multiply three matrices—A, B, and C—shown in the image below:

Figure 10.3
Multiplying them together could proceed with the grouping (AB)C, where A and B are multiplied together first, and then that result is multiplied by C. Alternatively, we could group them as A(BC) and first multiply B by C, followed by A multiplied by the result. Which would be better, or would it even matter?
Let’s figure this out by first considering the A(BC) grouping. The figure below illustrates this example. With this grouping, calculating the BC multiplication yields 20,000 multiply operations. Multiplying A by this result gives another 10,000 for a total of 30,000 multiply operations.
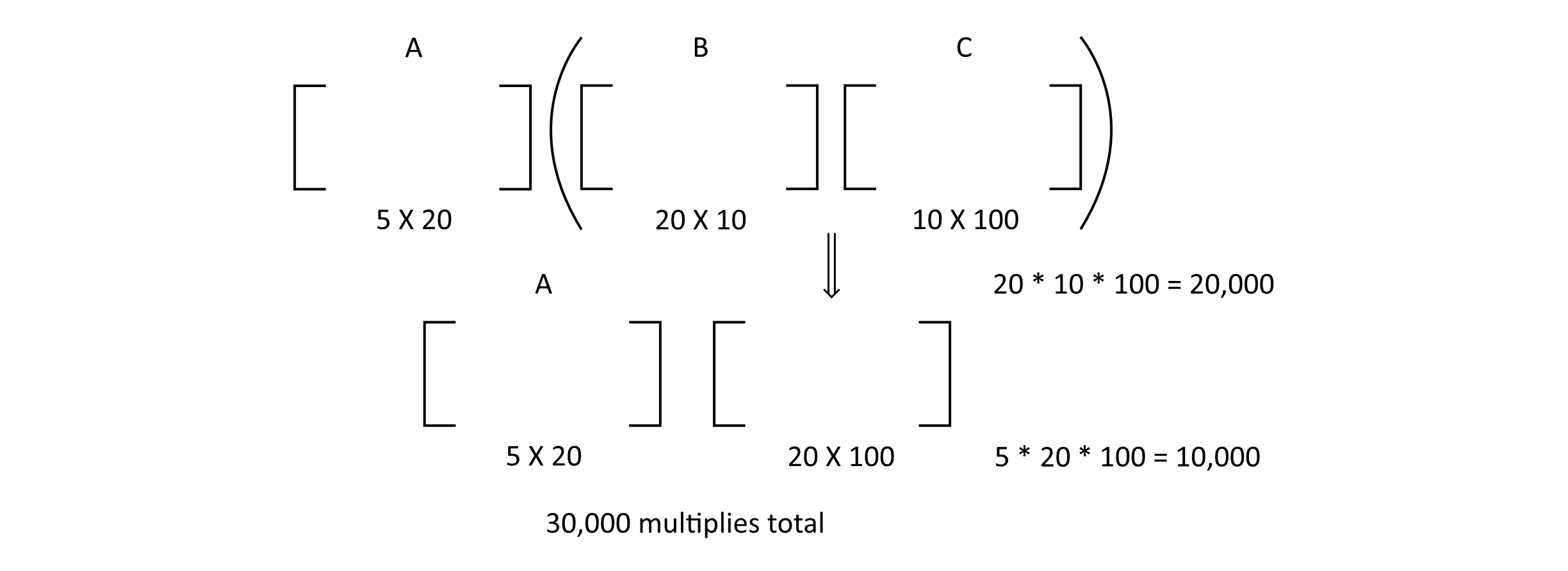
Figure 10.4
Next, let’s consider the (AB)C grouping. The following figure shows a rough diagram of this calculation. The AB matrix multiplication gives a cost of 1,000 multiply operations. Then this result multiplied by C gives another 5,000. We now have a total of 6,000 multiply operations for the (AB)C grouping over the other. This represents a fivefold decrease in cost!
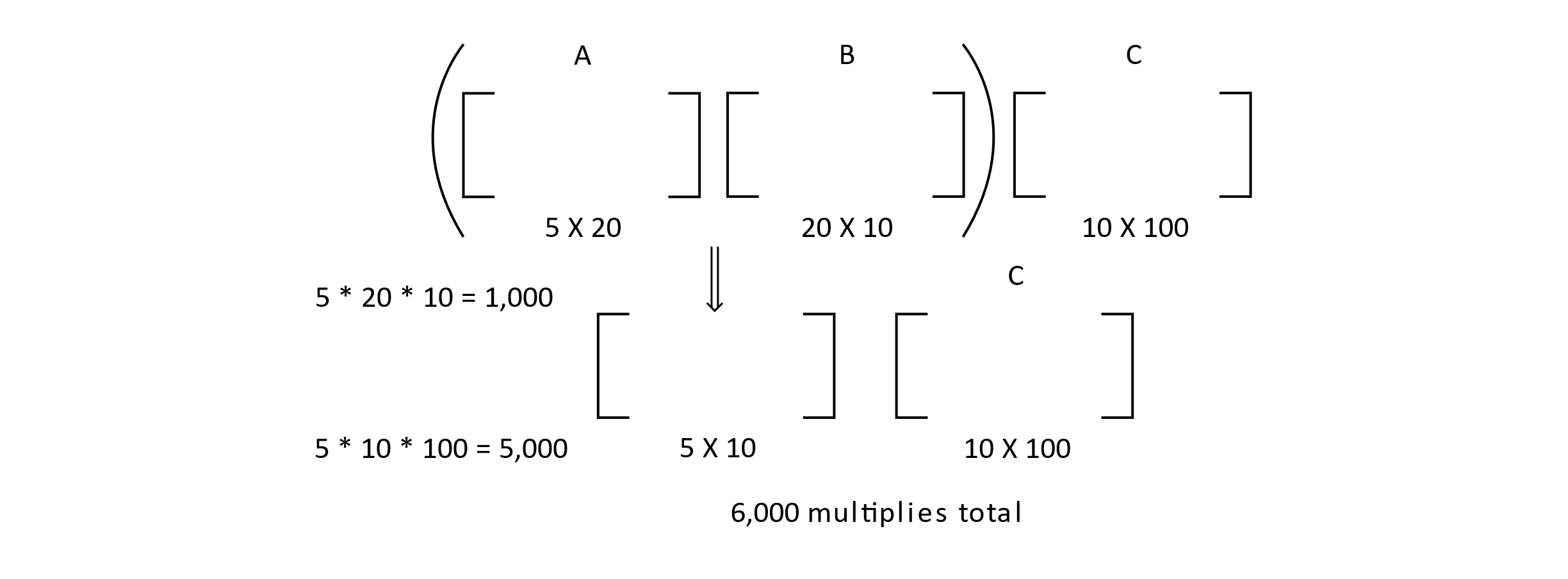
Figure 10.5
This example illustrates that the order of multiplication definitely matters in terms of computational cost. Additionally, as the matrices get larger, there could be significant cost savings when we find an optimal grouping for the multiplication sequence.
A Recursive Algorithm for Optimal Matrix-Chain Multiplication
We are interested in an algorithm for finding the optimal ordering of matrix multiplication. This corresponds to finding a grouping with a minimal cost. Suppose we have a chain of 5 matrices, M0 to M4. We could write their dimensions as a list of 6 values. The 6 values come from the fact that each sequential pair of matrices must be compatible for multiplication to be possible. The figure below shows this chain and gives the dimensions as a list.
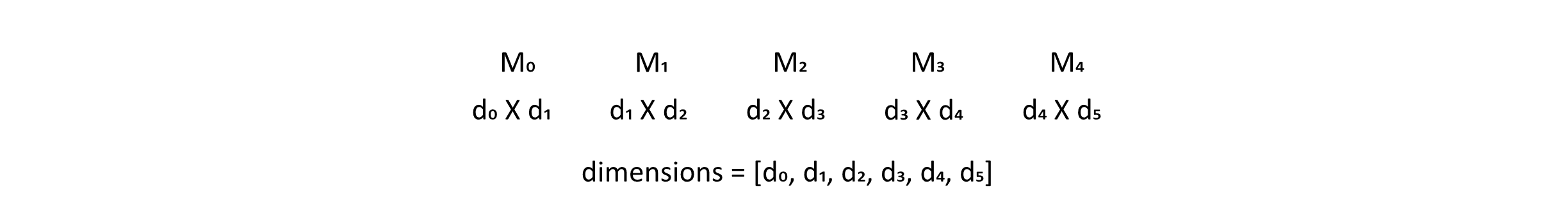
Figure 10.6
An algorithm that minimizes the cost must find an optimal split for the final two matrices. Let’s call these final two matrices A and B. For the result to be optimal, then A and B must both have resulted from an optimal subgrouping. The possible splits would be
(M0) (M1 M2 M3 M4) = AB with a split after position 0
(M0 M1) (M2 M3 M4) = AB with a split after position 1
(M0 M1 M2) (M3 M4) = AB with a split after position 2
(M0 M1 M2 M3) (M4) = AB with a split after position 3.
We need to evaluate these options by assessing the cost of creating the A and B matrices (optimal subproblems) as well as the cost of the final multiply, with matrix A being multiplied by B. A recursive algorithm would find the minimal cost by checking the minimum cost among all splits. In the process of finding the cost of all these four options for splits, we would need to calculate the optimal splits for other sequences to find their optimal groupings. This demonstrates the feature of optimal substructure, the idea that an optimal solution could be built from optimal subproblems.
For the first grouping, we have A = M0 and B = (M1 M2 M3 M4). To calculate the cost of this split, it is assumed that A and B have been constructed optimally. This means that a recursive algorithm considering this split must then make a recursive call to find the minimal grouping for (M1 M2 M3 M4) for the B matrix. This in turn would trigger another search for the optimal split among (M1) (M2 M3 M4) (M1 M2) (M3 M4) and (M1 M2 M3) (M4). We can also see that this would trigger further calls to optimize each sequence of 3 matrices and so on. You may be able to imagine that this recursive process has a high branch factor leading to an exponential runtime complexity in the number of matrices. With n matrices, the runtime complexity would be even worse than O(2n), exponential time. It would follow an algorithm for calculating the Catalan numbers at O(3n).
A general outline of the recursive algorithm would be as follows. We will consider an algorithm to calculate the minimal cost of multiplying a sequence of matrices starting at some matrix identified by the start index and including the ending matrix using an end index. The base case of the algorithm is when start and end are equal. The cost of multiplication of only one matrix is 0 as there is no operation to perform. The recursive case calculates the cost of splitting the sequence at some split position. There will be n − 1 split positions to test when considering n matrices where n = end − start + 1, and the recursive algorithm will need to find the minimum of the options for the best split position.
To complete the recursive algorithm, we will introduce a function to calculate the cost of the final multiplication. This could be a simple multiplication of the correct dimensions, but we will introduce and explain this function to make the meaning clear and to simplify some of the code (which would otherwise include a lot of awkward indexing). The figure below illustrates what is meant by the final multiplication:
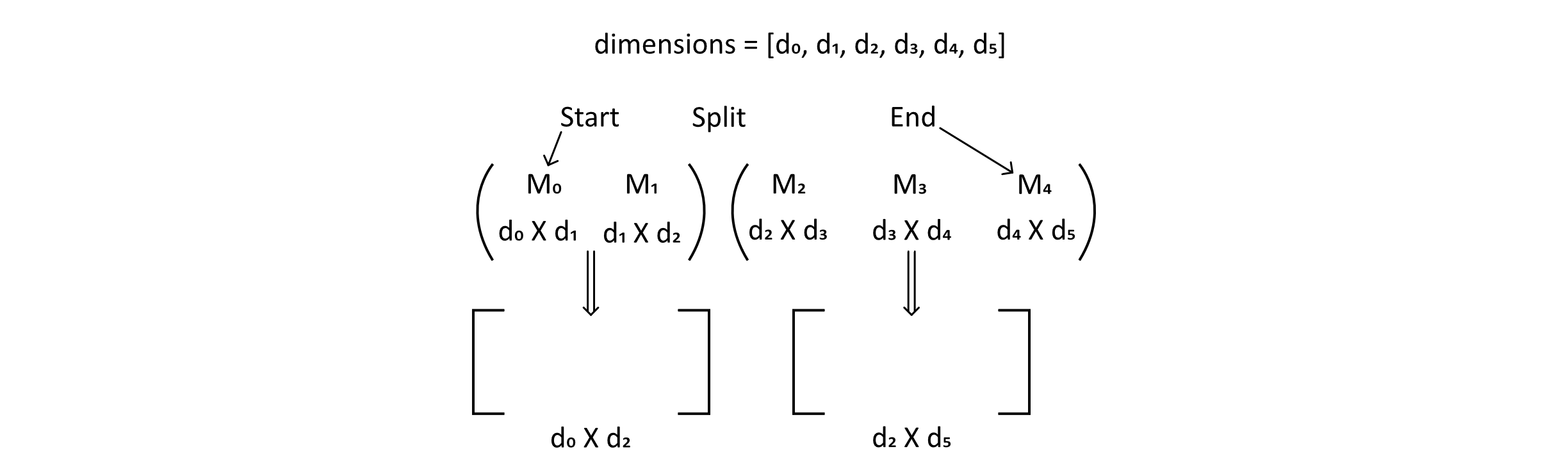
Figure 10.7
Suppose we are calculating the number of multiplications for a split at index 1 (or just after M1). The algorithm would have given the optimal cost for constructing the left matrix and the right matrix, but we would still need to calculate the cost of multiplying those together. The left matrix would have dimensions of d0 by d2 and the right matrix would have dimensions of d2 by d5. Using the dimensions list and indexes for start, split, and end, we can calculate this cost. The function below performs this operation in a way that might make the meaning a little clearer. Notice that for matrix i, the dimensions of that matrix are di by di+1.

With this helper function, we can now write the recursive algorithm.

This algorithm only calculates an optimal cost, but it could be modified to record the split indexes of the optimal splits so that another process could use that information. The optimal cost of multiplying all matrices in the optimal grouping could be calculated with a call to recursiveChainOpt(dimensions, 0, 4). This algorithm, while correct, suffers from exponential time complexity. This is the type of situation where dynamic programming can help.
A Dynamic Programming Solution
Let’s think back to our precious example for a moment. Think specifically about the first two groupings we wanted to consider. These are (M0) (M1 M2 M3 M4) and (M0 M1) (M2 M3 M4). For the first grouping, we need to optimize the grouping of (M1 M2 M3 M4) as a subproblem. This would involve also considering the optimal grouping of (M2 M3 M4). Optimally grouping (M2 M3 M4) is a problem that must be solved in the process of calculating the cost of (M0 M1) (M2 M3 M4), which is the second subproblem in the original grouping. From this, we see that there are overlapping subproblems. Considering this problem meets the criteria of optimal substructure and overlapping subproblems, we can be confident that dynamic programming will give us an advantage.
The logic behind the dynamic programming approach is to calculate the optimal groupings for subproblems first, working our way through larger and larger subsequences and saving their optimal cost. Eventually, the algorithm minimizes the cost of the full sequence of matrix multiplies. In this calculation, the algorithm queries the optimal costs of the smaller sequences from a table. This algorithm uses two tables. The first table, modeled using a 2D array, stores the calculated optimal cost of multiplying matrices i through j. This table will be called costs. The second table holds the choice of split index associated with the optimal cost. This table will be called splits. While the algorithm calculates costs, the splits are the important data that can be used to perform the actual multiplication in the right order.
The algorithm is given below. It begins by assigning the optimal values for a single matrix. A single matrix has no multiplies, so when calculating a matrix chain multiplication with a sequence of 1, the cost is 0. Next, the algorithm sets a sequence length starting at 2. From here, start and end indexes are set and updated such that the optimal cost of all length 2 sequences in the chain are calculated and stored in the costs table. Next, the sequence length is increased to 3, and all optimal sequences of length 3 are calculated by trying the different options for the splitIndex. The splitIndex is updated in the splits table each time an improvement in cost is found. We should note that we again make use of the MAX value, which acts like infinity as we minimize the cost for a split. The process continues for larger and larger sequence lengths until it finds the cost of the longest sequence, the one including all the matrices.

Complexity of the Dynamic Programming Algorithm
Now we have seen two algorithms for solving the optimal matrix chain multiplication problem. The recursive formulation proved to be exponential time (O(2n)) with each recursive call potentially branching n − 1 times. The dynamic programming algorithm should improve upon this cost; otherwise, it would not be very useful. One way to reason about the complexity is to think about how the tables get filled in. Ultimately, we are filling in about one-half of a 2D array or table. This amounts to filling in the upper triangular portion of a matrix in mathematical terms. Our table is n by n, and we are filling in n(n+1)/2 values (a little over half of the n-by-n matrix). So you may think the time complexity should be O(n2). This is not the full story though. For every start-end pair, we must try all the split indexes. This could be as bad as n − 1. So all these pairs need to evaluate up to n − 1 options for a split. We can reason that this requirement would lead to some multiple of n2*n or n3 operations. This provides a good explanation of the time complexity, which is O(n3). This may seem expensive, but O(n3) is profoundly better than O(3n). Moreover, consider the difference between the number matrices and the number multiplications needed for the chain multiplication. For our small example of 3 matrices (our n in this case), we saw the number of multiply operations drop by 24,000 when using the optimal grouping, and our n was only 3. This could result in a significant improvement in the overall computation time, making the optimization well worth the cost.
Longest Common Subsequence
Another classic application of dynamic programming involves detecting a shared substructure between two strings. For example, the two strings “pride” and “ripe” share the substring “rie.” For these two strings, “rie” is the longest common subsequence or LCS. There are other subsequences, such as “pe,” but “rie” is the longest or optimal subsequence. These subsequence strings do not need to be connected. They can have nonmatched characters in between. It might seem like a fair question to ask, “Why is this useful?” Finding an LCS may seem like a simple game or a discrete mathematics problem without much significance, but it has been applied in the area of computational biology to perform alignments of genetic code and protein sequences. A slight modification of the LCS algorithm we will learn here was developed by Needleman and Wunsch in 1970. That algorithm inspired many similar algorithms for the dynamic alignment of biological sequences, and they are still empowering scientific discoveries today in genetics and biomedical research. Exciting breakthroughs can happen when an old algorithm is creatively applied in new areas.
Defining the LCS and Motivating Dynamic Programming
A common subsequence is any shared subsequence of two strings. A subsequence of a string would be any ordered subset of the original sequence. An LCS just requires that this be the longest such subsequence belonging to both strings. We say “an” LCS and not “the” LCS because there could be multiple common subsequences with the same optimal length.
Let’s add some terms to better understand the problem. Suppose we have two strings A and B with lengths m and n, respectively. We can think of A as a sequence of characters A = {a0, a1, …, am−1} and B as a sequence of the form B = {b0, b1, …, bn−1}. Suppose we already know that C is an LCS of A and B. Let’s let k be the length of C. We will let Ai or Bi mean the subsequence up to i, or Ai = {a0, a1, …, ai}. If we think of the last element in C, Ck−1 must be in A and B. For this to be the case, one of the following must be true:
- ck−1 = am−1 and ck−1 = bn−1. This means that am−1 = bn−1 and Ck−2 is an LCS of Am−2 and Bn−2.
- am−1 is not equal to bn−1, and ck−1 is not equal to am−1. This must mean that C is an LCS of Am−2 and B.
- am−1 is not equal to bn−1, and ck−1 is not equal to bn−1. This must mean that C is an LCS of A and Bn−2.
In other words, if the last element of C is also the last element of A and B, then it means that the subsequence Ck−2 is an LCS of Am−2 and Bn−2. This is hinting at the idea of optimal substructure, where the full LCS could be built from the Ck−2 subproblem. The other two cases also imply subproblems where an LCS, C, is constructed from either the case of Am−2 (A minus its last element) and B or the case of A and Bn−2 (B minus its last element).
Now let’s consider overlapping subproblems. We saw that our optimal solution for an LCS of A and B could be built from an LCS of Am−2 and Bn−2 when the last elements of A and B are the same. Finding an LCS of Am−2 and Bn−2 would also be necessary for our other two cases. This means that in evaluating which of the three cases leads to the optimal LCS length, we would need to evaluate the LCS of Am−2 and Bn−2 subproblems and potentially many other shared problems with shorter subsequences. Now we have some motivation for applying dynamic programming with these two properties satisfied.
A Recursive Algorithm for Longest Common Subsequence
Before looking at the dynamic programming algorithm, let’s consider the recursive algorithm. Given two sequences as strings, we wish to optimize for the length of the longest common subsequence. The algorithm below provides a recursive solution to the calculation of the optimal length of the longest common subsequence. Like with our matrix chain example, we could add another list to hold each element of the LCS, but we leave that as an exercise for the reader.

This algorithm will report the optimal length using a function call with the last valid indexes (length − 1) of each string provided as the initial index arguments. For example, letting A be “pride” and B be “ripe,” our call would be recursiveLCS(A, B, 4, 3), with 4 and 3 being the last valid indexes in A and B. Trying to visualize the call sequence for this recursive algorithm, we could image a tree structure that splits into two branches each time the else block is executed on line 7. In the worst case, where there are no shared elements and the length of an LCS is 0, this means a new branch generates 2 more branches for every n elements (assuming n is larger than m). This leads to a time complexity of O(2n).
A Dynamic Programming Solution
In a similar way to the matrix chain algorithm, our dynamic programming solution for LCS makes use of a table to record the length of the LCS for a specific pair of string indexes. Additionally, we will use another “code” table to record from which optimal subproblem the current optimal solution was constructed.
The following dynamic programming solution tries to find LCS lengths for all subsequences of the input strings A and B. First, a table, or 2D array, is constructed with dimensions (n+1) by (m+1). This adds an extra row and column to accommodate the LCS of a sequence and an empty sequence or nothing. A string and the empty string can have no elements in common, so the algorithm initializes the first row and column to zeros. Next, the algorithm proceeds by attempting to find the LCS length of all subsequences of string A and the first element of string B. For any index pair (i, j), the algorithm calculates the LCS length for the two subsequence strings Aj and Bi.
The core of the algorithm checks the three cases discussed above. These are the case of a match among elements of A and B and two other cases where the problem could be reformulated as either shortening the A string by one or shortening the B string by one. As the algorithm decides which of these options is optimal, we record a value into our “code” table that tells us which of these options was chosen. We will use the code “D,” “U,” and “L” for “Diagonal,” “from the Upper entry,” and “from the Left entry.” These codes will allow us to easily traverse the table by moving “diagonal,” “up,” or “left,” always taking an optimal path to output an LCS string. Let’s explore the algorithm’s code and then try to understand how it works by thinking about some intermediate states of execution.

To better understand the algorithm, we will explore our previous example of determining the LCS of “pride” and “ripe.” Let us imagine that the algorithm has been running for a bit and we are now examining the point where indexB is 2 and indexA is 4. The figure below gives a diagram of the current states of the lengths and codes tables at this point in the execution:
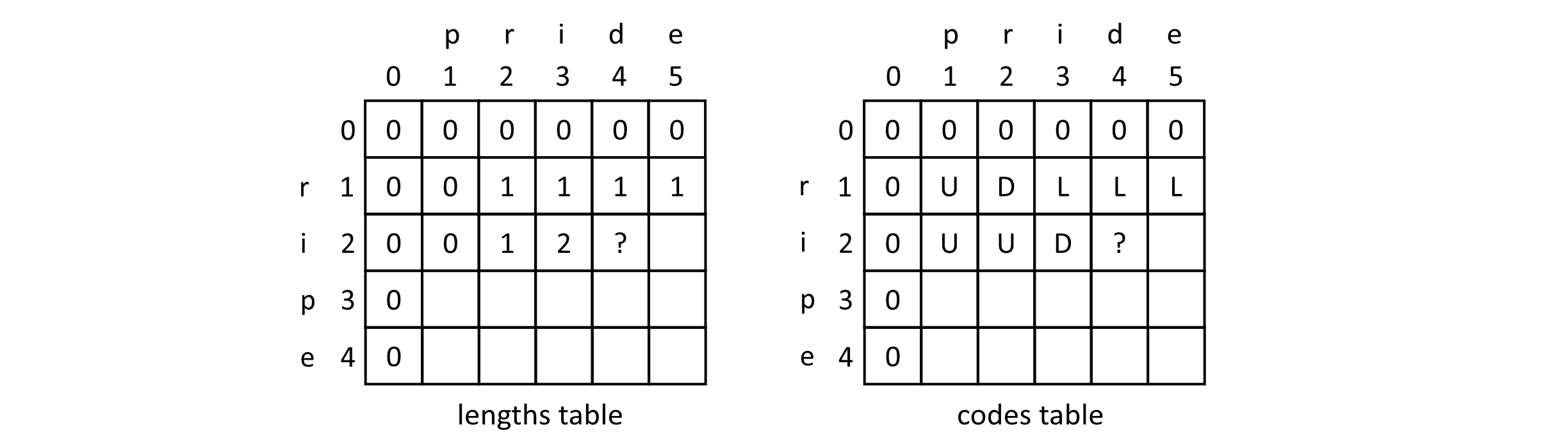
Figure 10.8
These tables can give us some intuition on how the algorithm works. Looking at the lengths table in row 2 and column 2, we see there is a 1. This represents the LCS of the strings “pr” and “ri.” They share a single element “r.” Moving over to the cell found in row 2 and column 3, we see the number 2. This represents the length of the LCS of the strings “pri” and “ri.” Now the algorithm is considering the cell in the row 2 column 4 position. The strings in these positions do not match, so this is not built from the LCS along the diagonal. The largest LCS value from the previous subproblems is 2. This means that the LCS of “prid” and “ri” is the same as the LCS of the shortened A string “pri” and “ri.” Since this is the case, we would mark a 2 at this position in the lengths table and make an “L” in this position in the codes table. These algorithms take time to understand fully. Don’t get discouraged if it doesn’t click right away. Try to implement it in your favorite programming language, and work on some examples by hand. Eventually, it will become clear.
Extracting the LCS String
Before we move on to the complexity analysis, let’s discuss how to read the LCS from the codes table. Depending on the design of your algorithm, you may be able to extract the LCS just from the strings and the lengths table, and the codes table could be omitted from the algorithm completely. We would like to keep things simple though, so we will just use the codes table. The algorithm below shows one method for printing the LCS string (in reverse order):

Complexity of the Dynamic Programming Algorithm
Now that we have seen the algorithm and an example, let’s consider the time complexity of the algorithm. The nested loops for the A and B indexes should be a clue. In the worst case, all increasing subsequences of each input string need to be compared. The algorithm fills every cell of the n-by-m table (ignoring the first row and column of zeros, which are initialized with a minor time cost). This gives us n * m cells, so the complexity of the algorithm would be considered O(mn). It might be reasonable to assume that m and n are roughly equal in size. This would lead to a time complexity of O(n2). This represents a huge cost savings over the O(2n) time cost of the recursive algorithm.
The space complexity is straightforward to calculate. We need two tables, each of size n+1 by m+1. So the space complexity would also be O(m*n), or, assuming m is roughly equal to n, O(n2).
A Note on Memoization
A related topic often appears in discussions of dynamic programming. The main advantage of dynamic programming comes from storing the result of costly calculations that may need to be queried later. The technique known as memoization does this in an elegant way. One approach to memoization allows for a function to keep a cache of tried arguments. Each time the function is called with a specific set of arguments, the cache can be queried to see if that result is known. If the specific combination of arguments has been used before, the result is simply returned from the cache. If the arguments have not been seen before, the calculation proceeds as normal. Once the result is calculated, the function updates the cache before returning the value. This will save work for the next time the function is called with the same arguments. The cache could be implemented as a table or hash table.
The major advantage of memoization is that it enables the use of recursive style algorithms. We saw in chapter 2 that recursion represents a very simple and clear description of many algorithms. Looking back at the code in this chapter, much of it is neither simple nor clear. If we could have the best of both worlds, it would be a major advantage. Correctly implementing memoization means being very careful about variable scope and correctly updating the cache when necessary to make sure the optimal value is returned. You must also be reasonably sure that querying your cache will be efficient.
Summary
Dynamic programming provides some very important benefits when used correctly. Any student of computer science should be familiar with dynamic programming at least on some level. The most important point is that it represents an amazing reduction in complexity from exponential O(2n) to polynomial time complexity O(nk) for some constant k. Few if any other techniques can boast of such a claim. Dynamic programming has provided amazing gains in performance for algorithms in operations research, computational biology, and cellular communications networks.
These dynamic programming algorithms also highlight the complexity associated with implementing imperative solutions to a recursive problem. Often writing the recursive form of an algorithm is quite simple. Trying to code the same algorithm in an imperative or procedural way leads to a lot of complexity in terms of the implementation. Keeping track of all those indexes can be a big challenge for our human minds.
Finally, dynamic programming illustrates an example of the speed-memory trade-off. With the recursive algorithms, we only need to reserve a little stack space to store some current index values. These typically take up only O(log n) memory on the stack. With dynamic programming (including memoization styles), we need to store the old results for use later. This takes up more and more memory as we accumulate a lot of partial results. Ultimately though, having these answers stored and easily accessible saves a lot of computation time.
Exercises
- Think of some other recursive algorithms that you have learned. Do any of them exhibit the features of optimal substructure and overlapping subproblems? Which do, and which do not?
- Try to implement the dynamic programming algorithm for optimal matrix chain multiplication. Next, implement a simple procedure that calculates the cost of a naïve matrix multiplication order that is just a typical left-to-right multiplication grouping. Randomly generate lists of dimensions, and calculate the costs of optimal vs. naïve. What patterns do you observe? Are there features of matrix chains that imply optimizations?
- Try to implement a recursive function to print the optimal parenthesization of the matrix multiplication chain given the splits table. Hint: Accept a start and end value, and for each split index s (splits[start][end]), recursively call the function for (start, s) and (s + 1, end).
- Implement the recursive LCS algorithm in your language of choice, and extend it to report the actual LCS as a string. Hint: You may need to use a data structure to keep track of the current LCS elements.
- Extend the LCS algorithm to implement an alignment algorithm for genetic code (strings containing only {“a,” “c,” “g,” “t”} elements). This could be done by adding a scoring system. When the algorithm assesses a diagonal, check if it is a match (exact element) or a mismatch (elements are not the same). Calculate an optimal score using the following rules: Matches get +2, mismatches get −1, moving left or up counts as a “gap” and gets −2. Calculate the optimal alignment score using this method for the strings “acctg” and “gacta.”
References
Bellman, Richard. Eye of the Hurricane. World Scientific, 1984.
Cormen, Thomas H., Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, 2nd ed. Cambridge, MA: The MIT Press, 2001.
Needleman, Saul B., and Christian D. Wunsch. “A General Method Applicable to the Search for Similarities in the Amino Acid Sequence of Two Proteins.” Journal of Molecular Biology 48, no. 3 (1970): 443–453.
