
12 Hard Problems
Learning Objectives
After reading this chapter you will…
- understand how computer scientists classify problems.
- be able to define some of the most common classes of problems in computer science.
- be able to explain the relationship between P and NP problem classes.
- understand some key properties of NP-complete and NP-hard problems.
- understand the role of approximate solutions and heuristics in battling hard problems.
Introduction
Everyone in life faces hard problems. Figuring out what to do with your life or career can be hard. You may find it hard to choose between two delicious menu items. These problems, while “hard” in their own way, are not the kinds of hard problems we will be exploring in this chapter. In this chapter, we will introduce some of the key ideas that support the theory of computation, the theoretical foundation of computer science. The discovery of these concepts is rather recent in the history of science and mathematics, but these concepts provide some fascinating insight into how humanity may attempt to solve the most difficult problems.
In the following sections, we will introduce the most discussed complexity classes in theoretical computer science. These are the complexity classes of P, NP, NP-complete, and NP-hard. These classes highlight many interesting and important results in computer science. We will explore what makes problems “easy” or “hard” in a theoretical sense. We will then explore some concepts for tackling these hard problems using approximations and heuristics. Finally, we will end the chapter with a discussion of an “impossible” problem, the halting problem, and what this means for computability.
The goal of this chapter is to simply introduce some of the important theoretical results in computer science and to highlight some ways in which this knowledge can be practical to a student of computer science. We will not introduce a lot of formal definitions or attempt to prove any results. This chapter is to serve as a jumping-off point for further study and, hopefully, an inspiring introduction to some of science’s most profound discoveries about computing and problem-solving.
Easy vs. Hard
In some ways, what computer scientists view as an easy or hard problem is very simple to determine. Generally, if a problem can be solved in polynomial time—that is, O(nk) for some constant k—it is considered an easy problem. Another word that is used for this type of problem is “tractable.” Problems that cannot be solved in polynomial time are said to be “intractable” or hard. These include problems whose algorithms scale exponentially by O(2n), factorially by O(n!), or by any other function that grows faster than an O(nk) polynomial function. Remember though, we are thinking in a theoretical context. Supposing that k is the constant 273, then even with the small n of 2, 2273 is a number larger than the estimated number of atoms in the universe. In practice, though, few if any real problems have algorithms with such large degree polynomial scaling functions. By similar reasoning, some specific problem instances of our theoretically intractable problems can be exactly solved in a reasonable amount of time. In general, this is not the case though. Interesting problems in the real world remain challenging to solve exactly, but many of them can be approximated. These “pretty good” solutions can still be very useful. In the discussions below, we will mostly focus on time complexity, but a lot of theoretical study has gone into space complexity as well. Let’s explore these ideas a bit more formally.
The P Complexity Class
In our discussion of hard problems, we need to first define some sets of problems and their properties. First, let’s think about a problem that needs to be solved by a computer. A sorting problem, for example, provides an ordered list of numbers and asks that they be sorted. Solving this problem would provide the same numbers reordered such that they are all in increasing order. We know that there exist sorting algorithms that can solve this problem in O(n2) and even O(n log n) time. Problems such as these belong to the P complexity class. P represents the set of all problems for which there exists a polynomial time algorithm to solve them. This means that an algorithm exists for solving these problems with a time scaling function bounded by O(nk) for some constant k.
Strictly speaking, P is reserved only for decision problems, a problem with only a yes or no solution. This is not a serious limitation from our perspective. Many of the problems we have seen in this book can be easily reformulated as decision problems of equal difficulty. Suppose there is an algorithm, let’s identify it as A, that solves instances of a decision problem in P. If A can solve any instance of the problem in polynomial time, then we say that A decides that set of problem instances. For any input that is an instance of our problem, A will report 1. In this case, we say A accepts the input. If any input is not an instance of that decision problem, A will report 0. In this case, we say A rejects that input.
By framing our algorithms as decision problems, we can rely on some concepts from formal language theory. From this framework, we think about encoding our inputs as strings of 0 and 1 symbols. We should know numbers can be encoded in binary, but other types of data, such as images and symbol data, can also be so encoded. At some level, all their data are stored in binary on your phone or computer. We can use 0 and 1 as symbols to construct the strings of our binary language. In the formal language model, A acts as a language recognizer. If the input string is part of our specific language of problem instances, A will accept it as part of the language. If an input string is not part of the problem set of instances, A will reject it as we discussed in the previous paragraph. This is one of the formalizations that have been used to reason about problems in theoretical computer science. We will not explore formal languages any further here, but this model is equivalent to the practical problem-solving we have explored in this textbook. The language model also closely relates to the simplest theoretical model of computing, the Turing Machine.
The concept of determinism is another important idea to introduce in our discussion of the complexity class P. The P class is described as the class of deterministic polynomial time problems. This requires a bit of subtlety to describe accurately. For now, we will just say that the algorithms for solving problems in P function deterministically in a step-by-step fashion. This could be interpreted as meaning that the algorithms can only take one step at a time in their execution. This definition will make more sense as we discuss the next complexity class, NP, or the class of nondeterministic polynomial time problems.
The NP Complexity Class
We think of problems in P as being easy because “efficient” algorithms exist to solve them. By efficient, we mean having polynomial time complexity, O(nk). The NP complexity class introduces some problems that can be considered fairly hard. NP stands for nondeterministic polynomial time complexity. The NP class of problems introduces the idea of solution verification. If you were given the solution for an algorithm, could you verify that it was correct? Think about how you might verify that a list of numbers is sorted. How could you verify that 7! = 5040? I’m sure you can think of several ways to easily check these answers in a short amount of time. Again, we will focus on decision problems, but decision versions of all problems can be constructed such that we do not lose generality in this discussion. For a problem to be in NP, there must exist an algorithm A that verifies instances of the problem by checking a “proof” or “certificate.” You may think of the certificate as a solution to the problem that must be verified in polynomial time.
NP leaves the question of whether a problem can be solved quickly and considers whether the solution could be verified quickly. The nondeterministic part refers to the idea of ignoring how quickly the problem could be solved. We mentioned that a deterministic algorithm could take only one step at a time. We could think of a nondeterministic algorithm as one that could take many steps “at the same time.” One interpretation of this might be considering all options simultaneously. The main takeaway is that a correct solution must be verifiable in polynomial time for the problem to be a member of NP.
An Example of an NP Problem: Hamiltonian Cycle
At this point in our discussion, it may be helpful to examine a classic example of a problem in NP. A Hamiltonian cycle is a path in a graph that visits all nodes exactly once and returns to the path’s start. Finding this kind of cycle can be useful. Consider a delivery truck that needs to make many stops. A helpful path might be one that leaves the warehouse, visits all the necessary stops (without repeating any), and returns to the warehouse. For the example graph below, we may wish to solve the decision problem of “Given the graph G = {V, E}, does a Hamiltonian cycle exist?”
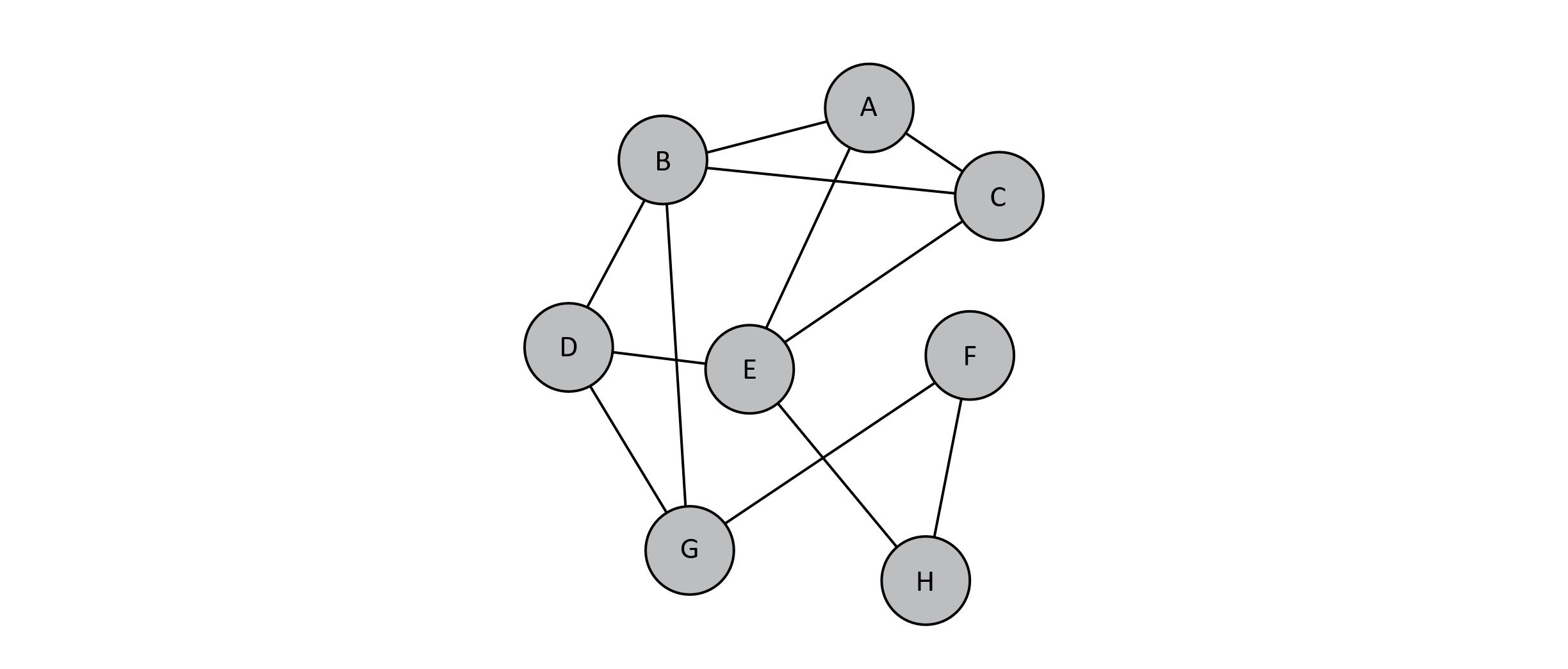
Figure 12.1
We will discuss the complexity of solving this problem soon, but for now, we will consider how to verify a solution to the problem. Suppose that we are given this problem and a potential solution. How would we verify the correctness of the solution? The “proof” or “certificate” of this problem could be the ordered list of vertices in the cycle. We could easily verify this solution by attempting to traverse the nodes (or vertices) in order along the graph. If we visit all the vertices and return to the starting vertex, the verification algorithm could report “yes.” This would only require work proportional to the number of nodes, so verifying a solution to the Hamiltonian cycle problem would have a time complexity of O(n), where n is the number of nodes in the graph. This means that this problem could be easily verified, and by “easily,” we mean it could be verified in polynomial time. For the above graph, a Hamiltonian cycle would be {E, A, C, B, D, G, F, H, E}. Note that we must return to the original position for the path to be a cycle. This is illustrated below:
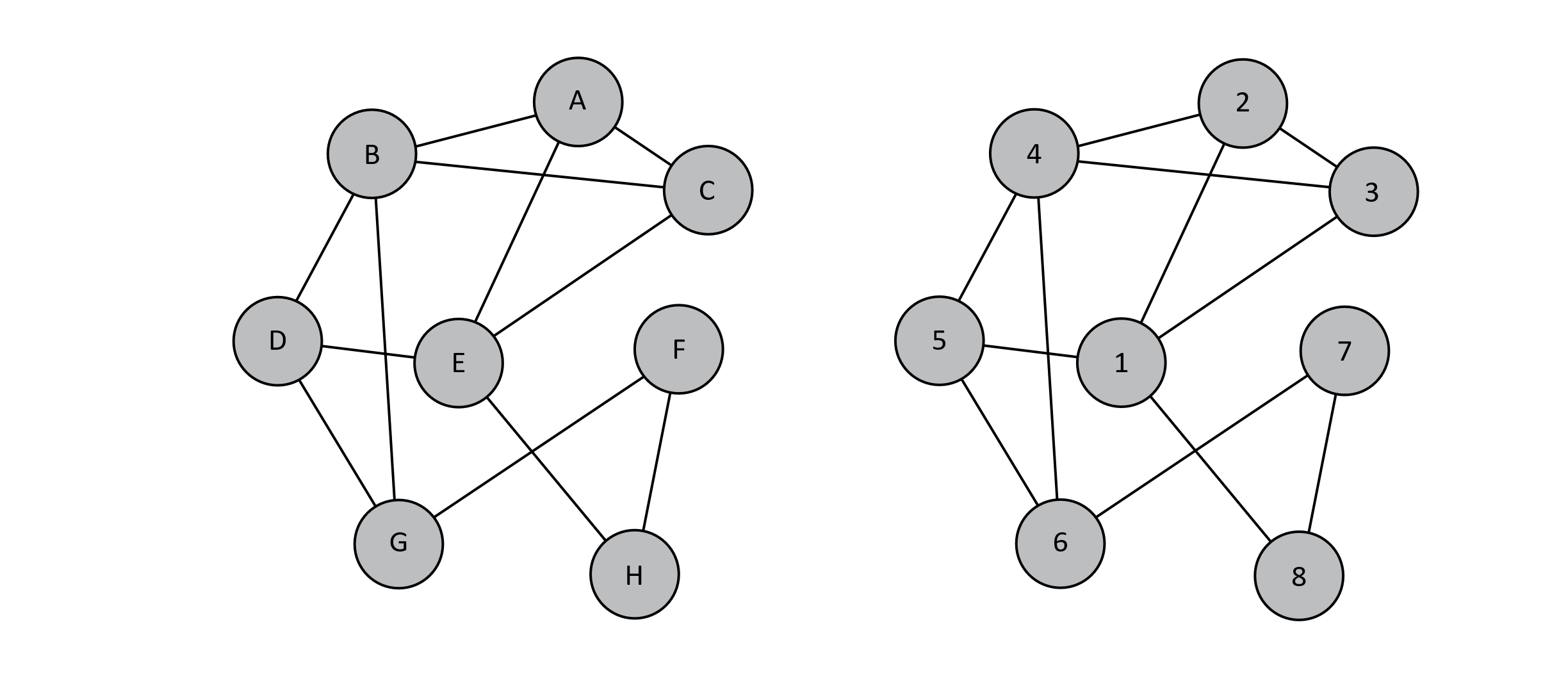
Figure 12.2
The fact that the Hamiltonian cycle problem can be easily verified may give the (false) impression that it is also easily solvable. This does not appear to be the case. One approach to solve it might be to enumerate all the possible cycles and verify each one. Each cycle would be some permutation of all the vertices. With n as the number of vertices in the graph, this means that there would be O(n!) possible orderings to check! This naïve algorithm is even slower than exponential time O(2n). In fact, one of the best algorithms known to solve it has a runtime complexity of O(2nn2)—better than O(n!) but still extremely slow for relatively small n.
Before we move on to the next section, let’s consider the P complexity class in the context of NP. It should be clear that any problem in P must also be in NP. If a problem can be easily solved, it should also be easily verified. Consider for a moment the opposite situation where a problem is easy to solve but difficult to verify. Struggling to verify a solution to a problem might call into question how easily it was solved. The complexity class P represents all problems solved in polynomial time, and it is a subset of the NP class. Now whether it is a “proper subset” or not of NP is a classic unsolved problem in computer science theory. A proper subset means that it cannot be equivalent to the NP class itself. From this discussion, it may seem as though P and NP are not the same set, but many brilliant mathematicians and scientists have attempted to prove or disprove this fact without any success for decades. Whether P = NP or not remains unknown. In the next section, we will discuss this further and highlight just why the P = NP or P ≠ NP question is so interesting.
Polynomial Time Reductions
In this section, we will introduce the idea of a reduction. Informally, the term “reduction” refers to a method of casting one problem instance as an instance of another problem such that solving the new “reduced” problem also solves the original. As we explore the next two complexity classes of NP-hard and NP-complete, we use this powerful idea of reductions. Using an efficient reduction to transform one problem into another would serve as a key to solving a lot of different problems.
We will briefly consider a classic problem known as the Circuit-Satisfiability Problem. This is often abbreviated as CIRCUIT-SAT, but this could also represent the set of all circuit satisfiability problems (or, specifically, their instances). Suppose we want to determine if a circuit composed of logic gates has some assignment to its inputs that makes the overall circuit output 1. The circuits are composed of logic gates that take inputs that are either 0 or 1, standing for either low or high voltage. The typical diagram for these gates is given below:
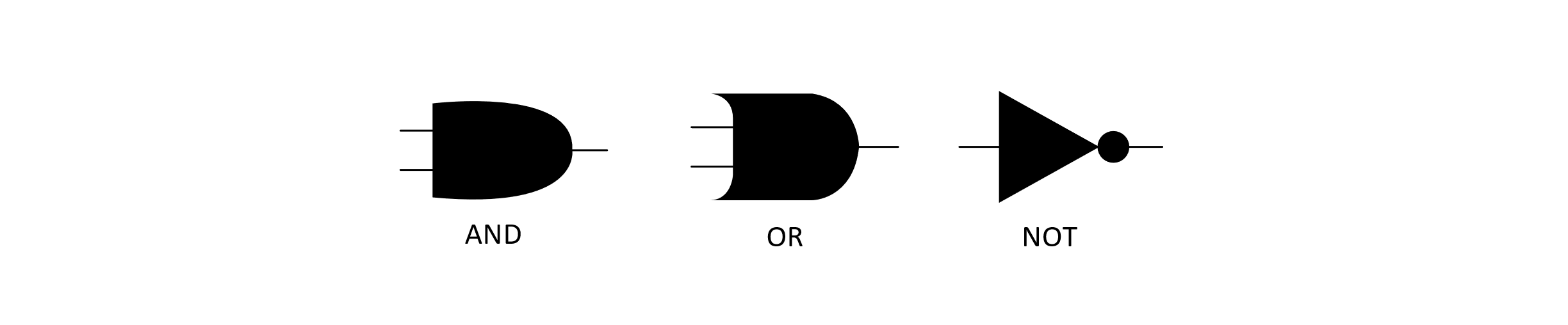
Figure 12.3
These gates correspond to their interpretation in mathematical logic. This means that the AND gate will output a 1 when both of its inputs are 1. We can compose these gates into larger circuits. The image below presents an example of a circuit that uses several of these gates and takes three inputs, marked X, Y, and Z:
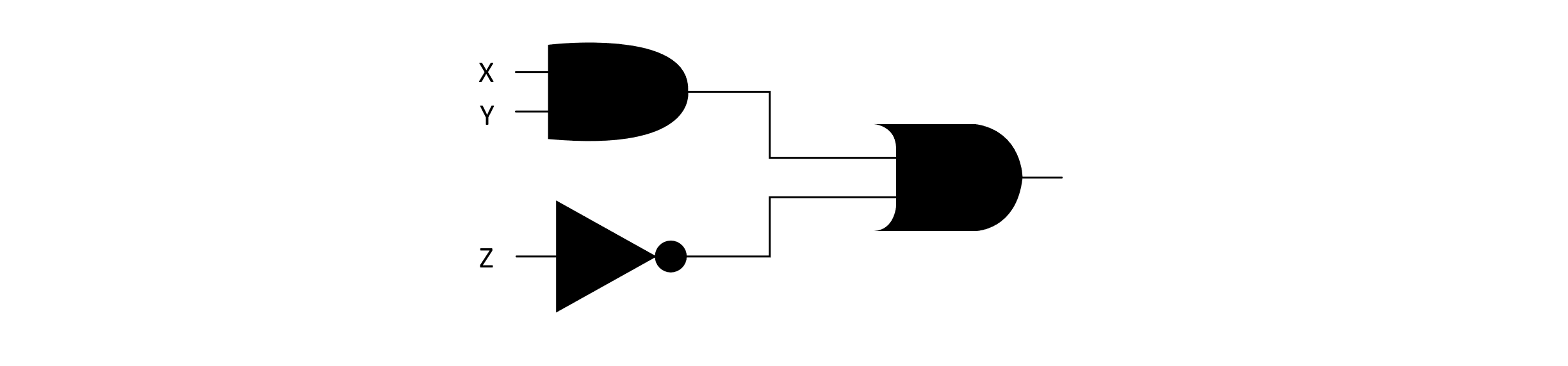
Figure 12.4
The decision problem for CIRCUIT-SAT would decide the question of “Given a representation of a circuit composed of logic gates, does an assignment of zeros and ones to the inputs exist that makes the overall circuit output 1?” Such an assignment of inputs is said to satisfy the circuit. One method of solving this problem would be to try all possible combinations of 0 and 1 assignments. Given n inputs, this would be attempting to try O(2n) possibilities. Given a potential solution, we could verify the assignment satisfies the circuit by simply simulating the propagation of input values through the sequence of logic gates. An algorithm for solving CIRCUIT-SAT problems would be very useful. Let’s look at why.
Suppose we have another problem we wish to solve: Given a logical formula, can we provide an assignment to the logical Boolean variables that satisfies the formula? To satisfy the formula means to find an assignment of true or false values to the variables that makes the overall formula true. This is known as the Boolean satisfiability problem, and these problem instances are usually referred to as the set SAT. A logical formula can be composed of variables and Boolean functions on those variables. These are the functions AND, OR, and NOT. These are usually written as the symbols ˄ (AND), ˅ (OR), and ¬ (NOT). Additionally, the formulas use parentheses to make sure there are no ambiguous connections. An example of a Boolean formula is given below:
(x ˄ y) ˅ (¬x ˄ z).
Formulas such as this can be used to model many problems in computer science. If we had an algorithm that could solve CIRCUIT-SAT problems, Boolean formula problems could be solved by first constructing a circuit that matched the formula and then passing that circuit representation to the algorithm that decides CIRCUIT-SAT. The figure below gives a circuit that corresponds to the Boolean formula given above:
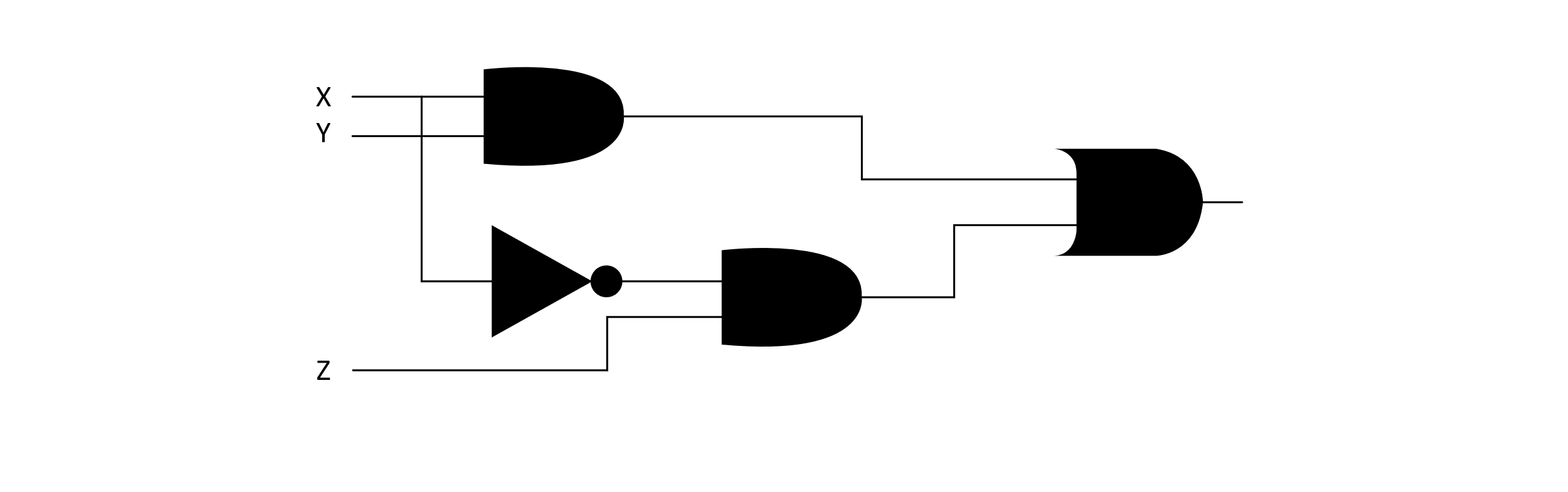
Figure 12.5
An assignment of 0 or 1 to the inputs of this circuit would correspond to an assignment of true or false to the Boolean variables of the formula. While not a formal proof, hopefully this illustration demonstrates how one instance of a problem can be cast into another and a solution to one can be used to solve the other. A key point is that this conversion must also be efficient. For this strategy to be effective, the reduction from one problem (SAT) to another problem (CIRCUIT-SAT) must also be efficient. If just doing the reduction was intractable and difficult, then we would not make any progress. We will only be interested in reductions that can be done in polynomial time. For this problem, we could create a procedure that would parse a string representation of the formula and generate a parse tree. From this tree, we could use each branching node to represent a logic gate, and from this, we could construct a representation of the circuit. Generating the parse tree might require O(n3) operations (this is an upper bound on some parsing algorithms), and converting the tree could be done using a tree traversal costing O(n). This means that for this case, we could efficiently “reduce” the SAT problem into an instance of CIRCUIT-SAT.
We will introduce the notation for reducibility here, as it will be helpful in the following discussions. Remember that we can also talk about the representations of problems as being strings in a language. We might say that SAT, or all the problems in SAT, represents a language L1. The problems in CIRCUIT-SAT represent the language L2. Now to capture the above discussion in this notation, we would write L1 ≤P L2, using a less than or equal to symbol with a P subscript. The meaning of L1 ≤P L2 is that L1 is polynomial-time reducible into an instance of L2. The less than or equal to symbol is used to mean that problems in L2 are at least as hard as problems in L1. The P subscript is there to remind us that the reduction must be doable in polynomial time for this to be a useful reduction.
Let’s provide one more example of a reduction. Another interesting and well-studied problem in computer science is the Traveling Salesman Problem or TSP. This problem tries to solve the practical task of minimizing the amount of travel between the different cities for a salesperson before they return home. Another way to cast the problem might be to ask, “What is the route that minimizes energy usage for a delivery truck such that it makes all its stops and returns to the warehouse?” You may already be thinking back to our discussion of Hamiltonian cycles. The TSP is looking for a minimum-cost tour, which is precisely a Hamiltonian cycle. To consider the decision version of the TSP, we would take a graph with edge weights representing the costs of traveling from one destination to another and a cost threshold k. The decision problem then asks, “Given the weighted graph G and the threshold k, does there exist a minimum cost tour with a cost at most k?” So an instance of the Hamiltonian cycle problem could be reduced to an instance of the TSP. Taking an instance of the Hamiltonian cycle problem, we could construct a new graph with all edge weights set to 0. This could be done easily in polynomial time by modifying the representation of the graphic. This new weighted graph could be passed to an algorithm from solving TSP with k set to 0. Let’s let the set of all instances of Hamiltonian cycle problems be HAM-CYCLE. This means that we have HAM-CYCLE ≤P TSP, and any algorithm that solves instances of TSP can solve instances of HAM-CYCLE.
The NP-Hard and NP-Complete Complexity Classes
Reductions serve as a key to solving problems by taking them from one type of problem and transforming them into another. We explored two examples of reductions in the previous section. The SAT problems are reducible to the CIRCUIT-SAT problems. The HAM-CYCLE problems are reducible to the TSP problems. Other clever results have demonstrated that three-coloring a graph is reducible to the SAT problems. Interestingly, there are algorithms that can solve any problem in NP by reducing them from other problem types into an instance of a specific NP problem. These problems represent the NP-hard complexity class. More formally, an NP-hard problem is a problem (language) L, such that for any problem L′ in NP, L′ ≤P L. In other words, any algorithm for solving an NP-hard problem could solve any problem in NP. All four of our problems—CIRCUIT-SAT, SAT, HAM-CYCLE, and TSP—are NP-hard. The Cook–Levin theorem proved an interesting result showing that SAT is both in NP-hard (can be used to solve any NP problem) and in NP (easily verifiable). The class of problems with these characteristics is known as the NP-complete problems.
Now we revisit the P = NP or P ≠ NP question. Why is this a big deal? Suppose a problem set (and algorithm) could be found that was in NP-complete and in P. This would mean we have an NP-hard problem that can be easily solved. This result would mean that any NP problem could be easily solved in O(nk) time. We would simply reduce any NP problem into an instance of our special problem and solve it in polynomial time. This scenario would be the incredible result of a P = NP reality. The question is still up for debate, and no one has been able to prove this fact or, more importantly, find the algorithm. A world in which all difficult problems could be easily solved would certainly be interesting. For now, it is unknown whether P = NP or P ≠ NP. Many believe that P ≠ NP is the more likely scenario, but it has never been proven.
Approximation Algorithms and Heuristics
We should discuss the practical matter of how to solve difficult problems. We have given a somewhat formal description of NP-Hard and NP-Complete complexity classes, but let’s reconsider these problems in practical terms. Suppose we need to solve a SAT problem with 60 variables, and we brute-force search by trying every combination of Boolean assignments and evaluating them. The brute-force search requires O(2n) operations. So with 60 variables, the number of combinations is on the order of 260. We call the set of all possible solutions the search space. If we assume a computer could check 2 billion of these possible assignment solutions per second (which is reasonable), we could expect the calculation to be completed in about 18 years. The worst-case exponential time complexity for exploring the search space means that solving these problems quickly is impossible even for relatively small n (< 100).
We want solutions very quickly and cannot wait 18 years to figure out our best delivery route for this morning’s deliveries. Delivery companies want to be efficient to conserve energy. Factories want to maximize output and keep their machines running. Sometimes a great approximate solution to an NP-complete problem can be found quickly. An approximate solution is not totally correct, but it may satisfy many of the problem’s requirements. Suppose that we found a SAT assignment that could satisfy most of our Boolean formula’s expressions in the previous example; then this might still be very useful. Many real-world problems can be modeled by NP-complete problems, so finding good approximations for them is important work.
Many strategies exist for finding good approximations. The search for a good approximation can be framed as an optimization problem. We want to optimize a current solution’s value toward the optimal value of a fully correct solution. One approach might be to randomly try many different solutions and calculate the value. Each time you find a solution with a better value, you save it as the current best. You let the algorithm run for a fixed amount of time. When the time is up, return the best solution that was found. In general, the search for a good approximation makes use of heuristics. Heuristics are strategies or policies that help direct a search algorithm toward better approximations. The hope is that the heuristic will help guide the search toward an optimal solution. Unfortunately, this is not a guarantee. Algorithms usually act on local information, so any heuristic might be guiding the search toward a local optimum while the global optimum is in the other direction. Developing heuristics for NP-complete problems is an active field of research. We will look at one heuristic, the greedy algorithm, and see how it might be applied to an NP-Hard problem.
The greedy algorithm uses the heuristic to always make the choice that maximizes the current value. To explore this heuristic, we will introduce another NP-hard problem. The bin packing problem seeks to optimally pack objects of different sizes into a fixed-size bin. Each item has a cost associated with it, and the bin has a capacity threshold where no items may be added that would push the total cost over the threshold. You can think of this as the bin getting full of stuff, and nothing else can be put in it. The example below gives an illustration of the bin packing problem:
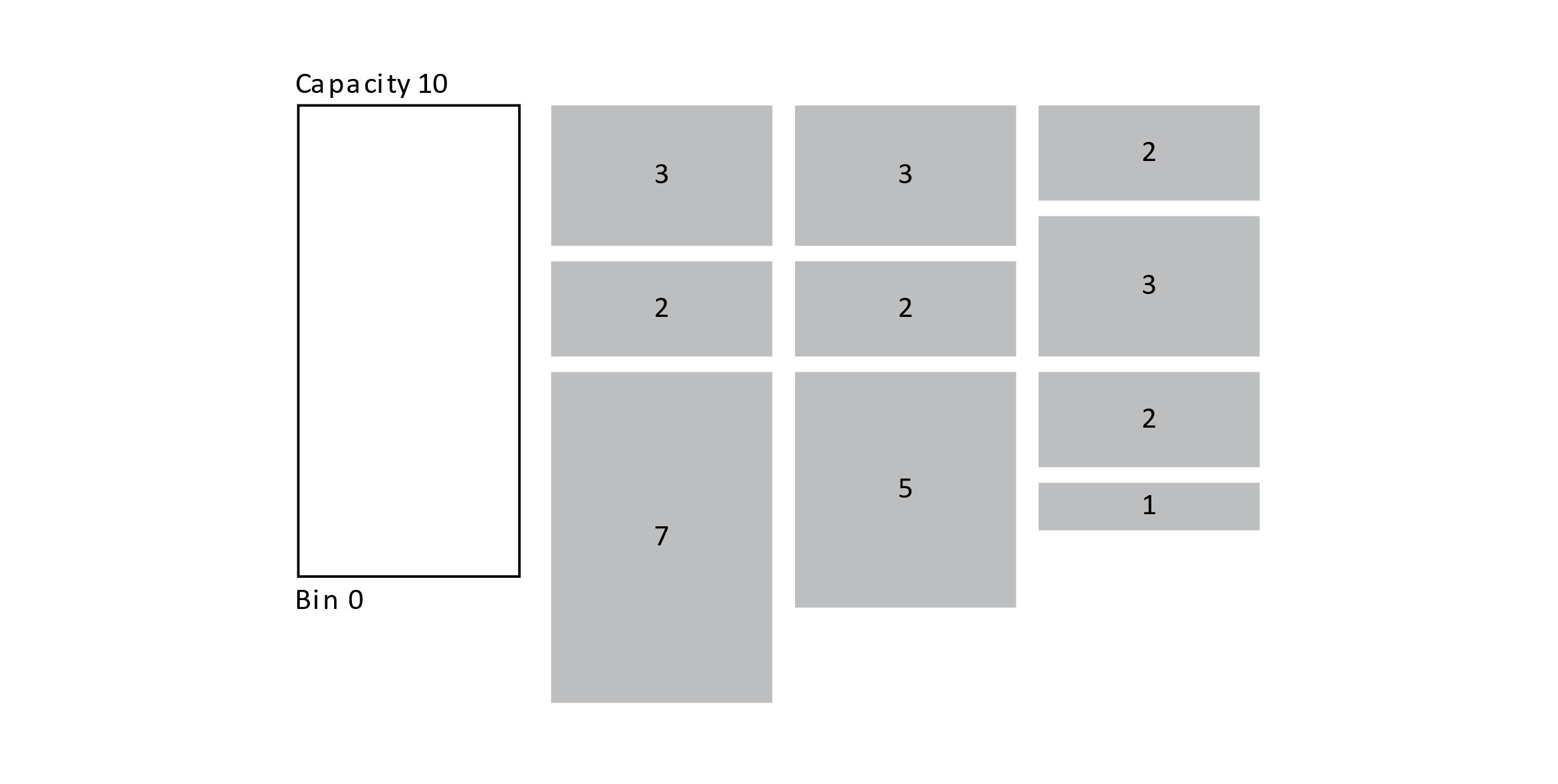
Figure 12.6
Given the boxes and their sizes, is there a way to pack all the boxes in the minimum number of bins? It might seem simple, but to solve this problem optimally, in general, might require a lot of time. One approach to finding the optimal number of bins would be to try all orderings of the items. Attempt to create bins by taking the items in the ordering and opening a new bin when the first is full. By trying all possible orderings of the items, the optimal bin number would be found, but this would take O(n!) time.
Using the greedy heuristic may help speed up our search even if the result may be suboptimal. A greedy algorithm tries to maximize or minimize the current value associated with a solution. For bin packing, a greedy strategy would be to always put the current item in the bin that minimizes the bin’s extra capacity. In other words, put the item in the bin where it fits the tightest. This is known as the Best Fit algorithm. An example of a Best Fit solution is presented below for the ordering {3, 3, 2, 3, 1, 2, 2, 5, 7, 2}. This assumes that the items arrive in a fixed order, and they cannot be reordered. We do get to choose which bin to place them in though. This is sometimes known as the “online” version of the bin packing problem.
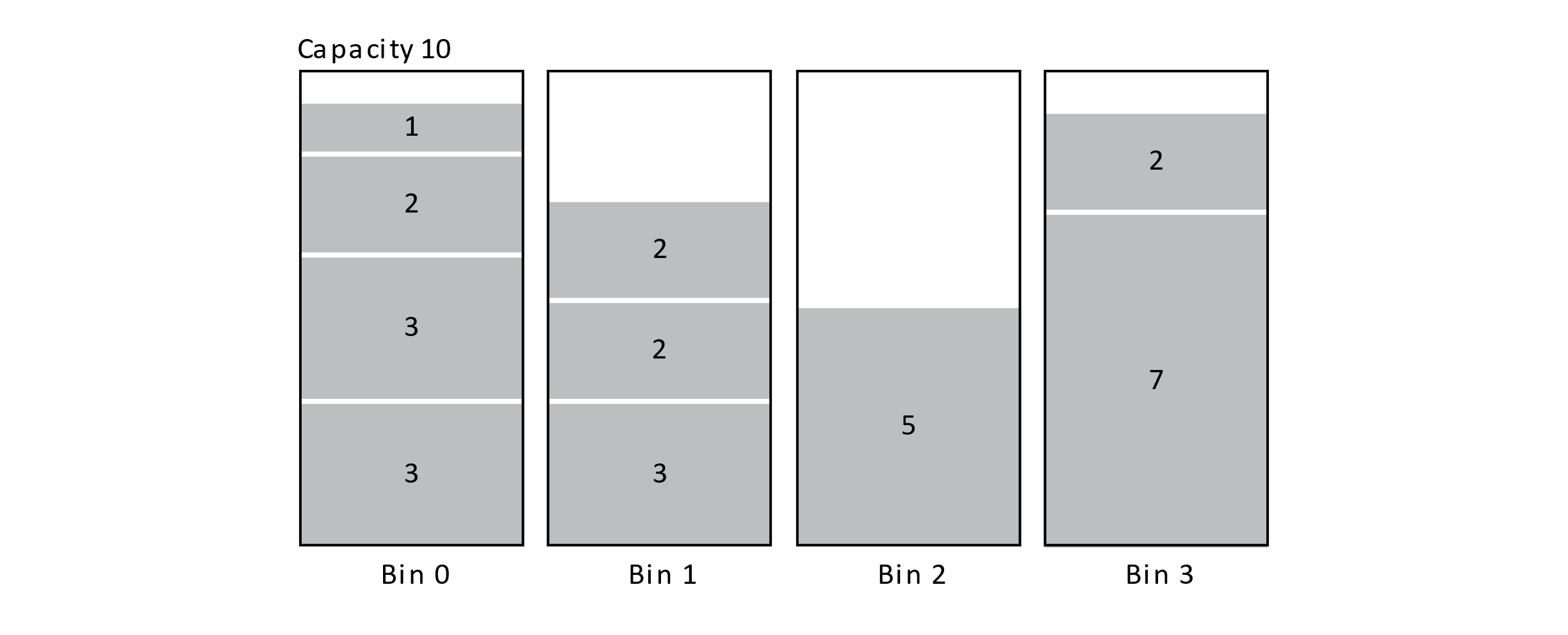
Figure 12.7
At each step, the algorithm tries to create the most tightly packed bin possible. A clever algorithm for Best Fit achieves an O(n log n) time complexity by querying bins by their remaining capacity in a balanced binary search tree. This algorithm is extremely fast compared to the brute-force method, but it is not optimal. Below is an optimal solution:
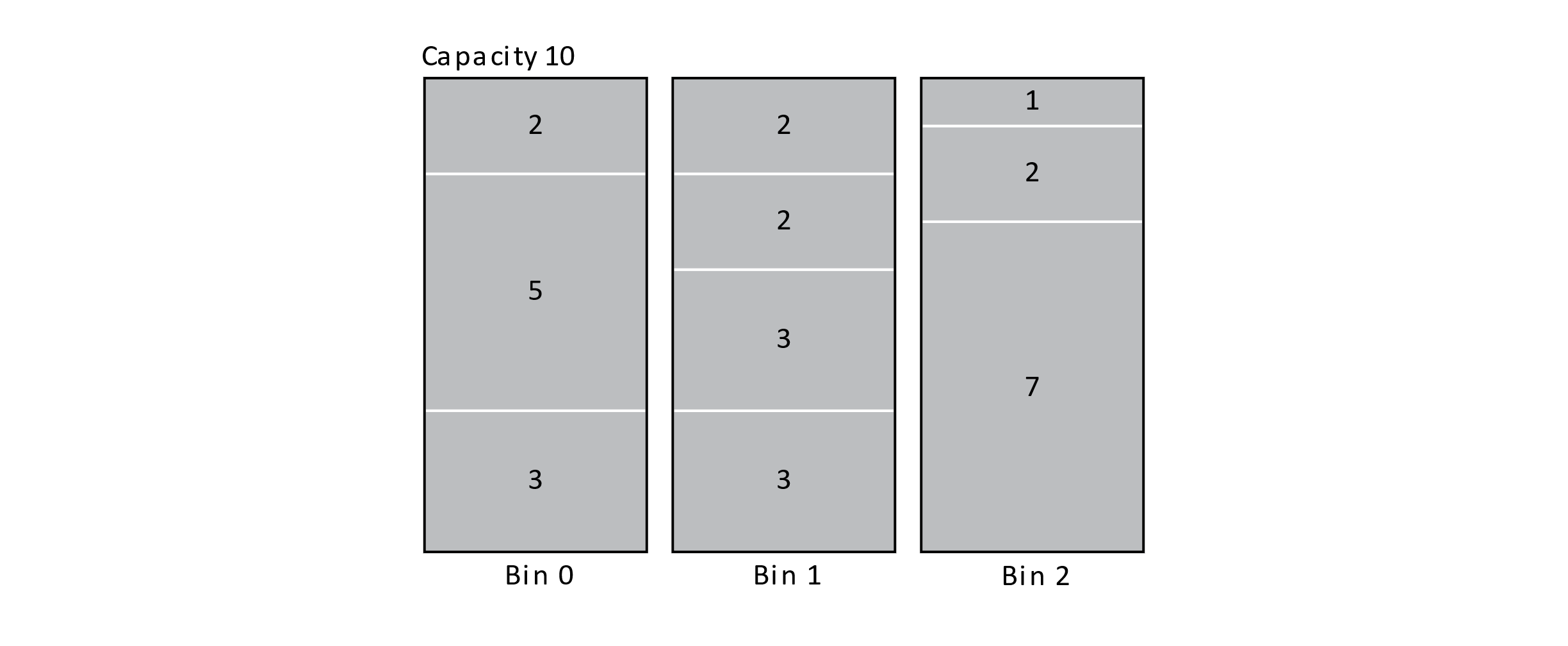
Figure 12.8
Depending on whether the items can be reordered or not, we may have the opportunity to first sort the items before applying Best Fit. Another good greedy algorithm for bin packing first sorts the items into descending order and then applies the Best Fit algorithm. This is known as Best Fit Decreasing. The figure below shows the result of applying Best Fit Decreasing to our block problem. This strategy does yield an optimal solution in this case. This algorithm would also have an O(n log n) time complexity. These algorithms show the value of using a heuristic to discover a good approximate solution to a very difficult problem in a reasonable amount of time.
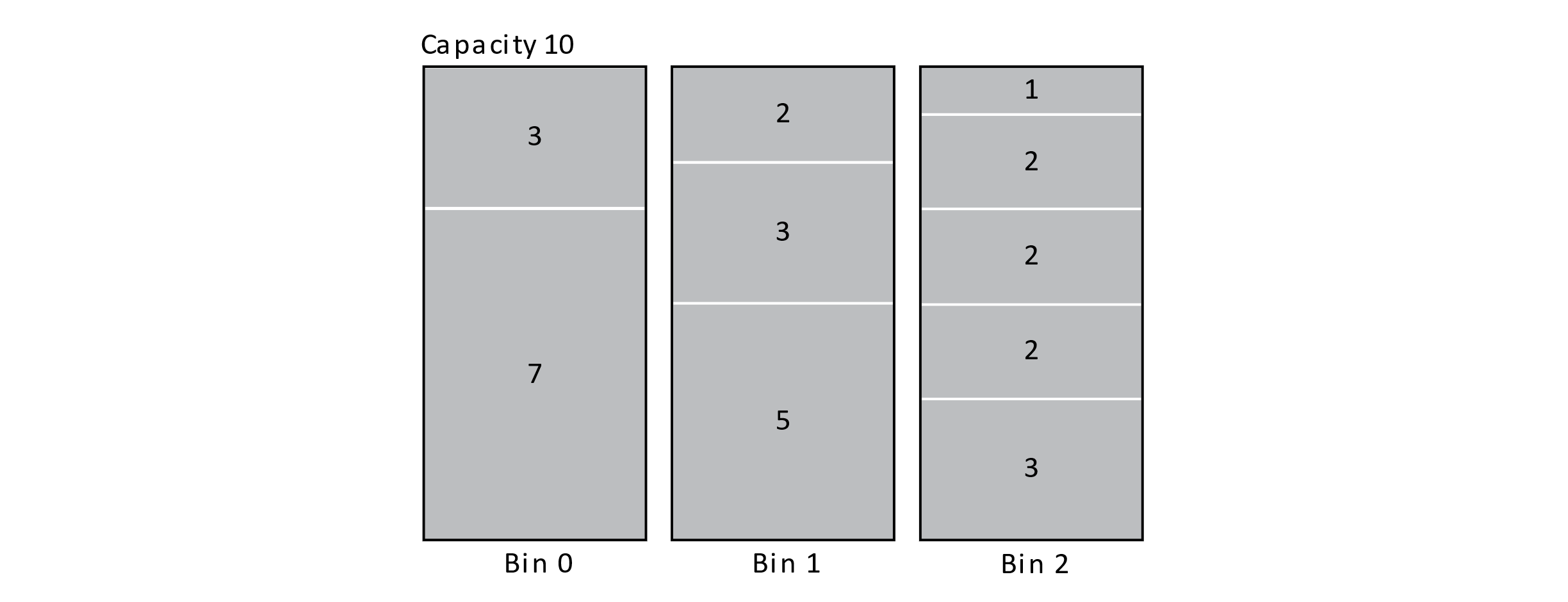
Figure 12.9
Bin packing provides insight into another feature of NP-complete and NP-hard problems. The decision version of the bin packing problem asks, “Given the n items and their sizes, can all items be packed into k or fewer bins?” This decision problem turns out to be NP-Complete. Given a potential solution and the number of bins, we can easily verify the number of bins used and the excess capacity in O(n) time. This fact confirms that the problem is in NP. Even with a target number of bins given, we would have to try overwhelmingly many configurations to ultimately determine if all the items would fit into the k bins. Now we may also be interested in determining the optimal number of bins. This decision problem might be asked as “Given the n items and their sizes, does the minimum packing require at most k bins?” Consider how we might verify that the optimal configuration was found. This means that we were given a solution and told it is optimal. We would now need to verify it. We could easily verify if the solution fits into the given number of bins. On the other hand, verifying that the number of bins for this solution is optimal would require considering all the possible solutions and checking that no other solution exists with a smaller number of bins. This means that the optimization version of this problem is not in NP. Therefore, the optimization problem is only NP-hard and not NP-complete. This pattern is common with NP-complete problems. If the decision version of a problem is NP-complete, its optimization version is usually only in NP-hard.
The Halting Problem
Before we end the chapter, we should discuss one of the classic problems in computer science, the halting problem. The halting problem illustrates the existence of “unsolvable” problems. Alan Turing proved the existence of a particular undecidable problem. The halting problem can be defined as asking the question “Given a representation of a computer program and the program input, will the program halt for that given input or run forever?” Turing’s argument proposed the existence of a program (an algorithm running on a machine) that could detect if another program would halt given a specific input. Let’s just informally say we have a function like checkIfHalts(program, input). If the input program would halt, meaning complete successfully, on the given input, then checkIfHalts would report yes. If the program would run forever given the input, checkIfHalts would report no. This would be an algorithm that decides the halting problem. Running this hypothetical algorithm on a machine would allow a scheme for deciding if a program would halt. The program checkIfHalts would simulate the program P with the given input and decide if P halts on the input. This machine is presented in a diagram below:

Figure 12.10
The interesting part of the argument suggests that our program runs with its own representation presented as the input. Let’s construct another machine using checkIfHalts that will run forever if the program halts given an input but will halt if the program runs forever (as verified by checkIfHalts). Below is a diagram of this machine. We will call it loopIfHalts.

Figure 12.11
Now we construct one final machine as follows. This machine will take as input the representation of a program and try to determine if that program would halt when given a representation of itself as input. This is done by copying the program and using the copy as input. This machine is presented below. We will just call this M(program).

Figure 12.12
Now suppose that we run M with a representation of M as the input. We can think of this as calling M(M). If the program M should halt given M as the input, then M(M) should run forever. However, this is exactly what we did. We passed M into M, and if it runs forever, then M(M) should halt. This leads to a contradiction. We have a paradox where M should both run forever and halt. Since we arrived at a contradiction and all these algorithms (loopIfHalts and M) are derived from our hypothetical checkIfHalts program, these facts indicate that such a program cannot exist. This means that the halting problem is undecidable. This proof was discovered by Alan Turing and published in 1936. It provided some of the first evidence of problems that were literally unsolvable. Now that’s a hard problem!
Summary
In this chapter we have explored many incredible results in computer science theory. We have explored what it means for a problem to be hard in a practical sense and in a theoretical sense. We also discussed the existence of impossible problems. These problems cannot be solved by any computer no matter how powerful or how much time they are given. Scientists are still working to understand whether P = NP or not. If this result turns out to be true, there may exist an efficient algorithm for solving many of our most difficult problems exactly. For now, though, no such algorithm is known. Computer scientists and humans in general never give up in the face of hard problems. We also explored the use of heuristics to help find suitable solutions when an exact solution might not be practical to find. These results in computer science theory will help you understand what makes problems hard and what to do about them.
Exercises
- Do some research on NP-complete problems. Find an NP-complete problem that was not discussed in this chapter. What is the current best time complexity for the problem?
- For your problem in exercise 1, how efficient in terms of runtime complexity are the current best approximation algorithms for the problem? What heuristics are used in the approximate solution?
- In your language of choice, implement the Best Fit algorithm for bin packing. Feel free to use a Linear Search rather than a balanced search tree. Use an interactive loop to allow the user to enter different sizes for each of the items and apply the greedy algorithm. Compare your implementation results to examples from this chapter.
- Try the following thought exercise. Consider the possibility that an algorithm is discovered that solves NP-complete problems in polynomial time. Write a paragraph describing how our society might change with the advent of this algorithm. Be sure to address some specific algorithms that could be made efficient and how solving them quickly might impact society.
References
Bellman, Richard. “Dynamic Programming Treatment of the Travelling Salesman Problem.” Journal of the ACM (JACM) 9, no. 1 (1962): 61–63.
Cormen, Thomas H., Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, 2nd ed. Cambridge, MA: The MIT Press, 2001.
Held, Michael, and Richard M. Karp. “A Dynamic Programming Approach to Sequencing Problems.” Journal of the Society for Industrial and Applied Mathematics 10, no. 1 (1962): 196–210.
Tovey, Craig A. “Tutorial on Computational Complexity.” Interfaces 32, no. 3 (2002): 30–61.
Turing, Alan Mathison. “On Computable Numbers, with an Application to the Entscheidungsproblem.” J. of Math. 58, no. 5(1936): 345–363.
