
11 Graphs
Learning Objectives
After reading this chapter you will…
- understand graphs as a mathematical structure.
- be able to traverse graphs using well-known algorithms.
- learn the scope of problems that can be addressed using graphs.
Introduction
Graphs are perhaps the most versatile data structure addressed in this book. As discussed in chapter 8, graphs at their simplest are just nodes and edges, with nodes representing things and the edges representing the relationships between those things. However, if we are creative enough, we can apply this concept to the following:
- roads between cities
- computer networks
- business flow charts
- finite state machines
- social networks
- family trees
- circuit design
If we can represent a given problem using a graph, then we have access to many well-known algorithms to help us solve that problem. This chapter will introduce us to graphs as well as some of these algorithms.
Brief Introduction to Graphs
A formal introduction to graphs may be found in most discrete math textbooks. The purpose of this section is not to provide such an introduction. Rather, we will focus more on the data structures used to represent graphs and the algorithms associated with them. Regardless, some basic vocabulary will prove useful.
Nodes are the primary objects under consideration in graphs. They are associated with other nodes by means of edges. Each edge is incident to two nodes. We define adjacent nodes of a given node as alternate nodes of incident edges. Adjacent nodes are sometimes referred to as neighbors. The degree of a node is the number of its incident edges or adjacent nodes (not including the node itself). Our depiction of graphs will look much like our depiction of trees. This should come as no surprise because, if you recall, trees are a special case of graphs.
If you cross-reference this chapter against more mathematically focused textbooks (which is strongly encouraged), you will find that some of these definitions vary. In particular, mathematical textbooks typically refer to nodes as vertices. They are also more precise in mathematical notation. For example, this chapter will use the symbol N to denote the number of nodes in the graph. In a mathematics context, the set of nodes is represented as set V and the number of nodes as |V| (or the cardinality of V).
Paths and cycles will play a large role in our graph algorithms. A path is some sequence of edges that allows you to travel from one node to another. A cycle is a path that starts and ends at the same node. Sometimes cycles are useful, but they often represent challenges in graph algorithms. Failing to detect a cycle in graph algorithms often results in implementations falling into endless loops.
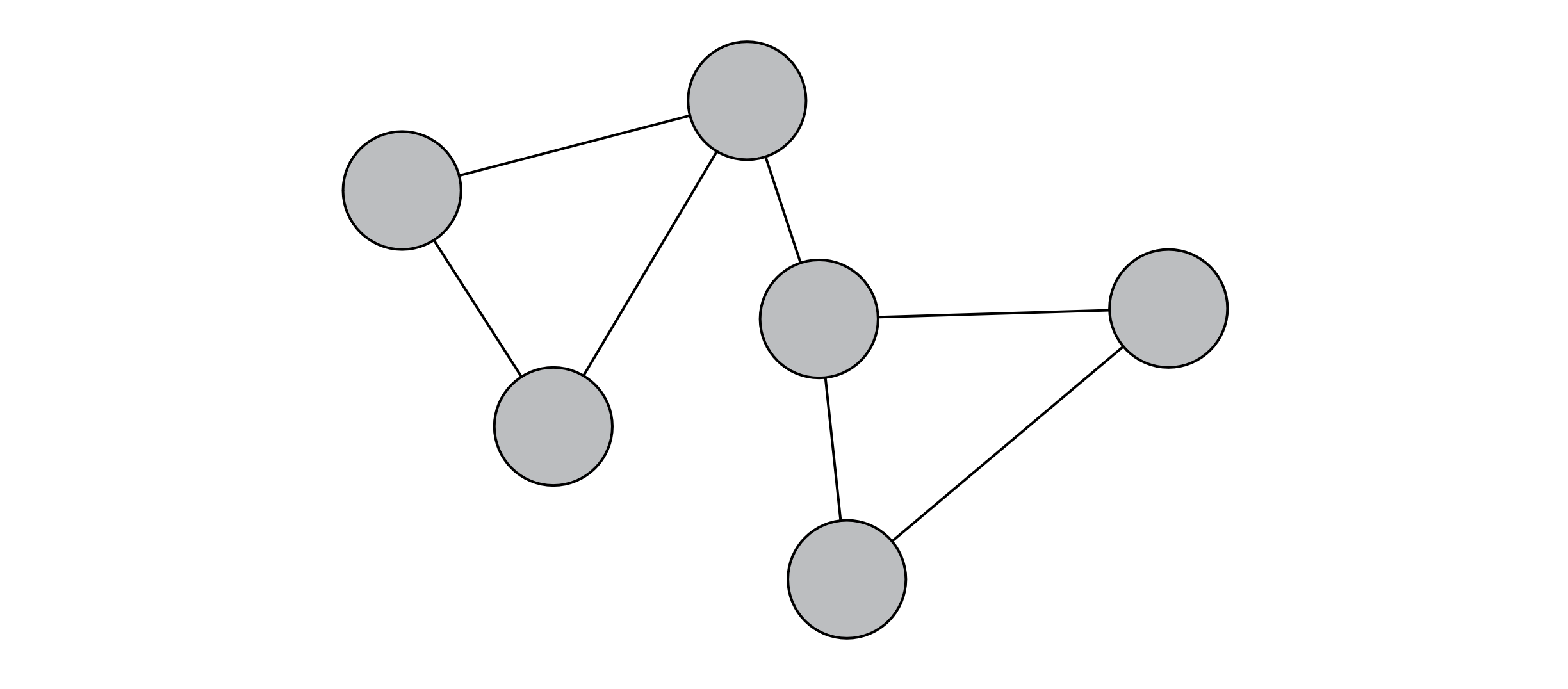
Figure 11.1
We will often need to consider whether a graph is directed or undirected. A directed graph is one in which each edge goes in a single direction. A network of flights across the United States is probably directed because every flight from city A to city B does not necessarily have a flight back from city B to city A. An undirected graph implies that we could traverse each edge in either direction. A network of roads between towns is likely undirected because most roads permit travel in both directions. If you reframe the network of roads, you could describe each lane as an edge, resulting in a directed graph. In our visual depictions of graphs, you will know whether a graph is directed or undirected by the use of arrows. Of the graphs below, the left graph represents an undirected graph, and the right represents a directed graph:
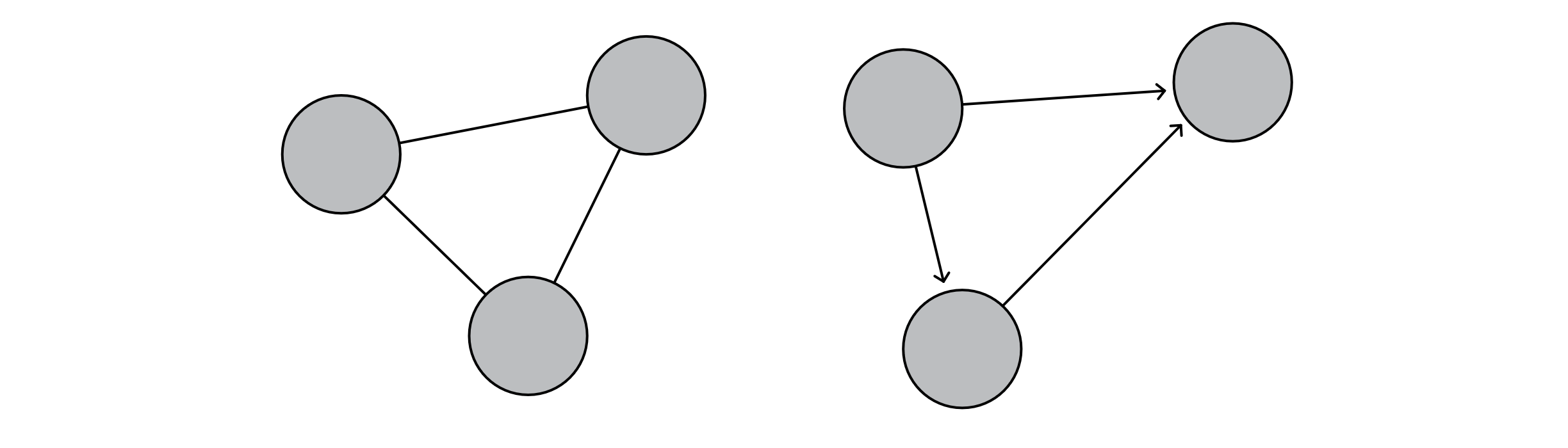
Figure 11.2
Another distinction we make will be between weighted and unweighted graphs. Weighted graphs have a numerical value associated with each edge, which represents the weight of that edge. For example, roads between cities have distances, and computer networks have measures of latency. Some graphs have no meaningful numerical value for edges and are considered unweighted. For example, social networks may have no meaningful weight for the relationship between two people. Much of this chapter will focus on graphs that are both weighted and directed.
Representations of Graphs
In a discrete math class, these graphs would be represented with basic set notation. We, however, have the additional burden of needing to represent this in a machine-readable format. Two main strategies exist for representing graphs in data structures, but there are numerous variations on these. We may choose to modify or augment these structures depending on the specific problem, language, or computing environment. For simplicity, we will only address the two main strategies.
Adjacency Matrices
An adjacency matrix is typically conceptualized as a table where the count of both rows and columns is equal to the number of nodes in the graph. Each row is assigned a node identifier, and each column is also assigned a node identifier. To determine whether an edge exists from node A to node B, we find the row for A and cross-reference B. The information in that cell of the table then provides information regarding the nature of the edge from A to B. Consider the following example:
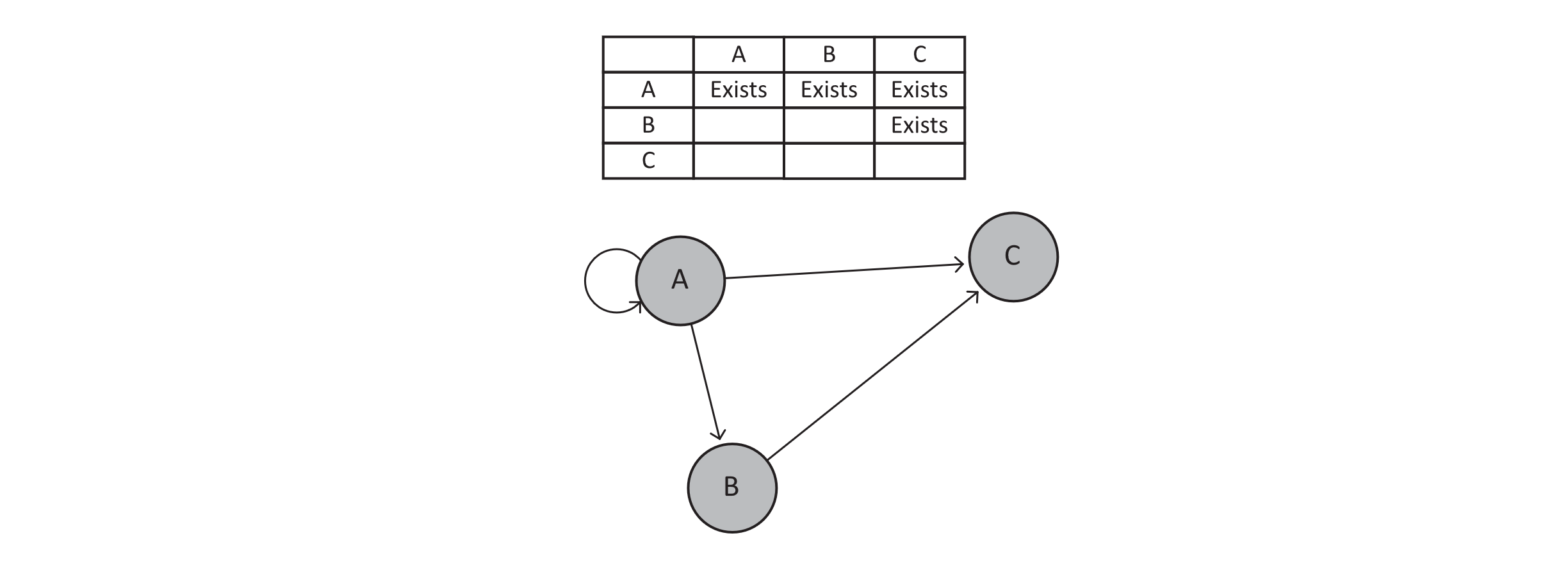
Figure 11.3
Notice that all we have asserted so far is that the intersection of the row and column supplies information about the nature of the edge. The data we store at each intersection depends on the type of graph we are modeling. Some considerations for adjacency matrices include the following:
- Weighted or Unweighted: If the graph is weighted, intersections will store the weight of the edge as some numeric type. In unweighted graphs, the intersection simply stores whether the edge exists.
- Directed or Undirected: If the graph is undirected, each nondiagonal intersection stores redundant information with exactly one other cell. For example, if an undirected graph has an edge between A and B, then the (A, B) intersection stores the same information as (B, A). On occasion, this may be desirable or undesirable. Naturally, a directed graph would store nonredundant information in each cell.
- Node Identities: The most logical choice for an underlying data structure would be a two-dimensional array. To leverage the constant-time lookups, we must provide an integer identifier for each node.
- Existence of Edges: Regardless of the points above, we must determine how to indicate that no edge exists. While many modern languages have some concept of a nullable type, you may not always want to use it. Particularly, nullable types often come with an implied increase in storage size (it may take 32 bits to store an integer, but storing an integer along with whether it exists is more information and consequently more bits). As a result, we might, by convention, choose a value to store in the matrix that indicates that no edge exists. Most weighted graphs in the natural world have strictly positive weights, so storing a −1 may serve as a useful indicator for a nonexistent edge. When working with an unweighted graph, simple 0s and 1s or true and false will suffice.
Adjacency Lists
If we perceive an adjacency matrix as a square table of edge information, an adjacency list is a jagged list of lists. The primary list has one entry for each node in the graph. Each of those entries then points to a list of adjacent nodes. The size of each secondary list depends on the degree of that node. Using the same graph as we used for adjacency matrices, we have the following adjacency list.
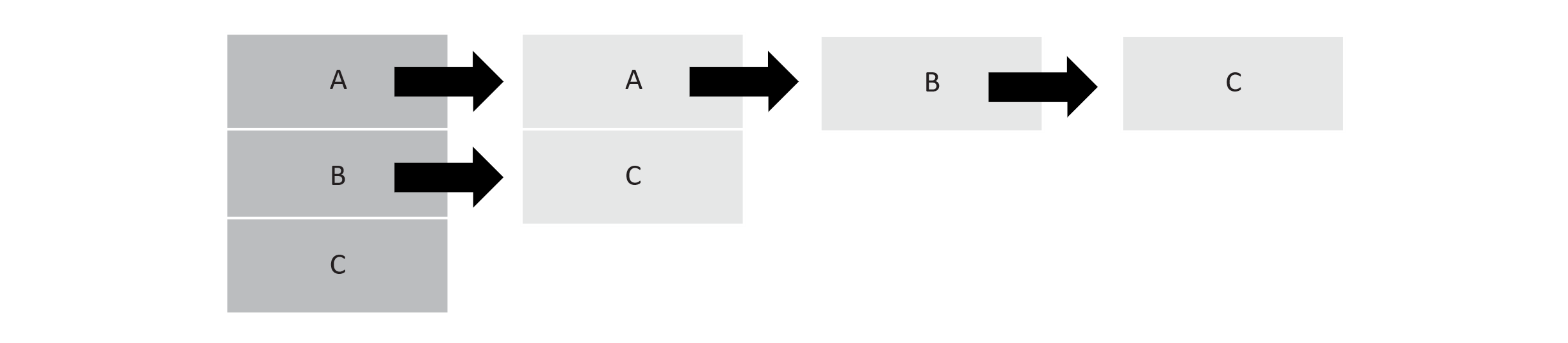
Figure 11.4
This is how adjacency lists are often portrayed visually, but we should note that the word “list” is in reference to the abstract data type list rather than a linked list. Also note that while the primary list clearly stores nodes, the secondary lists effectively store edges.
The list of lists nature of adjacency lists may be implemented in numerous ways. Considerations for concrete implementations include the following:
- Weighted or Unweighted: Weighted graphs require each entry in the secondary lists to store both the adjacent node’s identity and that edge’s weight. For this reason, we cannot store simple primitive types in each secondary entry. This implies that we will likely need some kinds of composite types such as objects or structs. Unweighted graphs are easily stored using the identity of the node and may not require additional types.
- Directed or Undirected: As with adjacency matrices, undirected graphs tend to lead toward redundancy in data. If an undirected graph has an edge between A and B, then A’s secondary list stores a reference to B, and B’s secondary list stores a reference to A. Directed graphs have no such concern.
- Underlying Data Structures: As with adjacency matrices, it may be convenient to identify each node using an integer. This allows us to leverage constant-time lookups when looking for nodes in primary or secondary lists. Unlike adjacency matrices, using arrays for secondary lists may pose additional challenges if edges are frequently added or removed (due to the fixed size of arrays).
Algorithms
Much like our discussion of trees, graph algorithms could consume chapters of a textbook. Rather than a broad survey of problems and known algorithms, we will address only three specific problems.
Traversal
Two frequent questions with graphs are (1) how we can visit each node and (2) if we can find a path between two nodes. They arise whenever we want to broadcast on a network, find a route between two cities, or help a virtual actor through a maze. We rely on two related algorithms to accomplish this task: breadth first traversal and depth first traversal. If we wish to perform a search, we simply terminate the traversal once the target node has been located.
Both algorithms depend on knowing some start node. If we are attempting to traverse all nodes, a start node may be chosen arbitrarily. If we wish to find a path from one node to another, we obviously must choose our start node deliberately. Both algorithms work from the same basic principle: if we wish to visit every node originating from some start node, we first visit its neighbors, its neighbors’ neighbors, and so on until all nodes have been visited. The primary distinction between both is the order in which we consider the next node. Breadth first spreads slowly, favoring nodes closest to the start node. Depth first reaches as deep as possible quickly. Below are examples of both traversals. Note that there is no unique breadth first or depth first traversal, but rather they are dependent on a precise implementation. The examples below represent possible traversals. There are other possibilities.
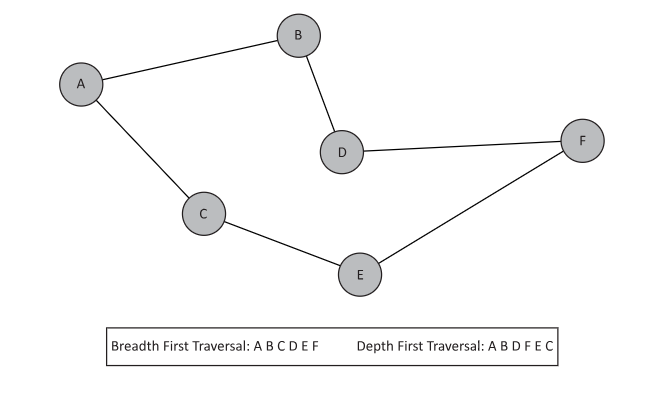
Figure 11.5
Note the difference in these traversals. Because breadth first starting from A will consider all A’s neighbors first, we will encounter C before we encounter F. Depth first will instead prioritize B’s neighbors before completing all of A’s neighbors. As a result, depth first reaches F before breadth first does.
In addition to the order in which we visit neighbors, we must also pay close attention to cycles. Recall that cycles are paths that start and end at the same node. In the depth first example above, what happens when we finally visit C only to find its neighbor is A? If we fail to recognize this as a cycle, we will again traverse A B D F E C and continue to do so indefinitely. We must avoid visiting already visited nodes. We will need to incorporate this into the algorithm as well.
Below is the pseudocode for a breadth first traversal. The function call Visit is simply a placeholder for some meaningful action you might take at each node (the simplest of which is simply printing the node identifier). It also assumes that node identifiers are integers.

Consider the above pseudocode along with figure 11.5. Assume a mapping from the letters A–F to integers 1–6, respectively. We first enqueue A. The queue is not empty, so we dequeue A. We have not yet visited it, so we visit, mark as visited, then enqueue the neighbors (B and C). In the case of breadth first, these two nodes were enqueued before D, E, and F. As a result, B and C will be visited before D, E, and F.
Also note the utility of the visited array. We visit a node, mark it as visited, then enqueue its neighbors. Once we have visited a node and enqueued its neighbors, the conditional on line 9 will prevent us from doing the same again. This is our mechanism for avoiding cycles.
This pseudocode describes a breadth first traversal but only requires a nominal change to make it a depth first traversal. Recall that after we visited A, we visited B and C. This was due to the first-in-first-out nature of queues. Consider what happens if we swap our queue for a stack. We visit A and now push B and C. C was the last node pushed, so a pop returns it. We then push A and E, which will eventually be popped before B. As a result, we prioritize nodes deep in the graph before ever considering B. In fact, we eventually consider B due to its adjacency to D rather than its adjacency to A.
Three aspects of graph algorithms make runtime analysis difficult. Because of these challenges, runtime analysis in this chapter will be less precise than in others but still descriptive as to roughly how much effort is required to perform the task at hand.
- We are typically working with two variables: count of nodes and count of edges. In the case of breadth first traversal, we can see that we will only visit each node once. We also enqueue and dequeue once for each edge (plus an additional enqueue/dequeue for the start node). This gives us a runtime of O(N + E), where N is the number of nodes and E is the number of edges.
- Analysis can be confusing because the upper bound of E is O(N2). An explanation of why can be found in Discrete Mathematics: An Open Introduction (found in the references for this chapter). There the author explains how the number of edges in a complete graph relates to the number of nodes. The explanation closely resembles the justification for O(N2) runtime of selection and Insertion Sort. Because of these two aspects, we can correctly say O(N+E) or O(N2), the choice of which is typically dependent on the current context. If we know that the number of edges is relatively low compared to the number of nodes, then use the sum of the two. If we know the graph to be highly connected, it is better to recognize the runtime as quadratic.
- Algorithms are typically presented conceptually without regard to precise implementations of graphs or auxiliary data structures. For example, if we are working in an object-oriented system, we may leverage adjacency lists, which limit our ability to perform constant-time indexing into the adjacent nodes. If we have no mapping from nodes to integers, we may have to perform Linear Searches to determine if nodes have been visited.
Single Source Shortest Path
While breadth first and depth first searches provide a path from a source to a destination, they do not guarantee an efficient path. Accomplishing such a task requires that the algorithm consider the weights of the edges that it traverses as well as the cumulative weights of edges already traversed. Numerous algorithms exist to find the shortest path from one node to another, but this section will focus on Edgar Dijkstra’s algorithm.
Dijkstra’s algorithm determines the shortest path between a source and destination node by maintaining a list of minimum distances required to reach each node already visited by the algorithm. It is an example of a greedy algorithm. This is a general strategy employed in algorithms, akin to the divide-and-conquer strategy employed in Binary Search or Merge Sort. Greedy algorithms make locally optimal choices that trend toward globally optimal solutions. In the case of Dijkstra’s (and Prim’s to follow), we only consider a single node at a time and use the information at that location in the graph to update the global state. If we carry this strategy out in clever ways, we can indeed determine the shortest path between two nodes without each step considering the entire graph.
In the following graph, consider finding the shortest path from A to D. Note that in the initial state, we acknowledge that the distance from the source node to itself is 0. This is analogous to enqueuing or pushing the source node in breadth first and depth first traversals. The primary control flow will again be a loop, which selects the next node to consider. Initializing some state again provides the loop with a logical place to begin. Also note that we maintain predecessors for each node whenever we update the distance to that node. This helps traverse the shortest path after the algorithm has been completed.
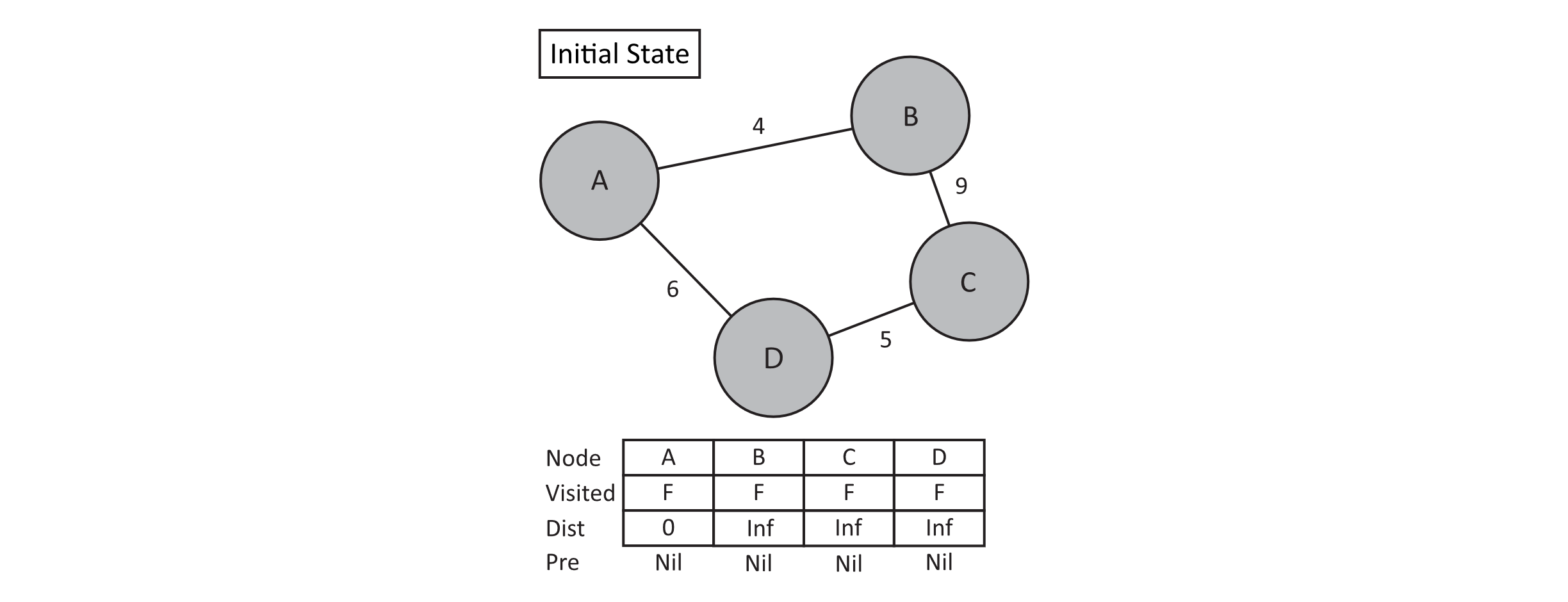
Figure 11.6
Now that we have some predefined state, we will begin our iteration to update the distance and predecessor arrays with the best information we know so far. Given the nodes we have visited so far (namely, A), we know we can reach B with a weight of 4 and predecessor node A. We can also reach C with weight 6 and predecessor node A. Note here that we are not claiming that the edge AB is the shortest path from A to B or that AC is the shortest path from A to C. What we are claiming is that of the nodes visited so far, the minimum weight paths to B or C are 4 and 6, respectively. We then start the next iteration by carefully choosing the next node to visit. It should be one that has not yet been visited so that we do not create cycles. Additionally, regarding the shortest path, we must choose the next node based on which has the minimum distance from the starting node. We then repeat this process until each node is visited or we reach some desired destination node.
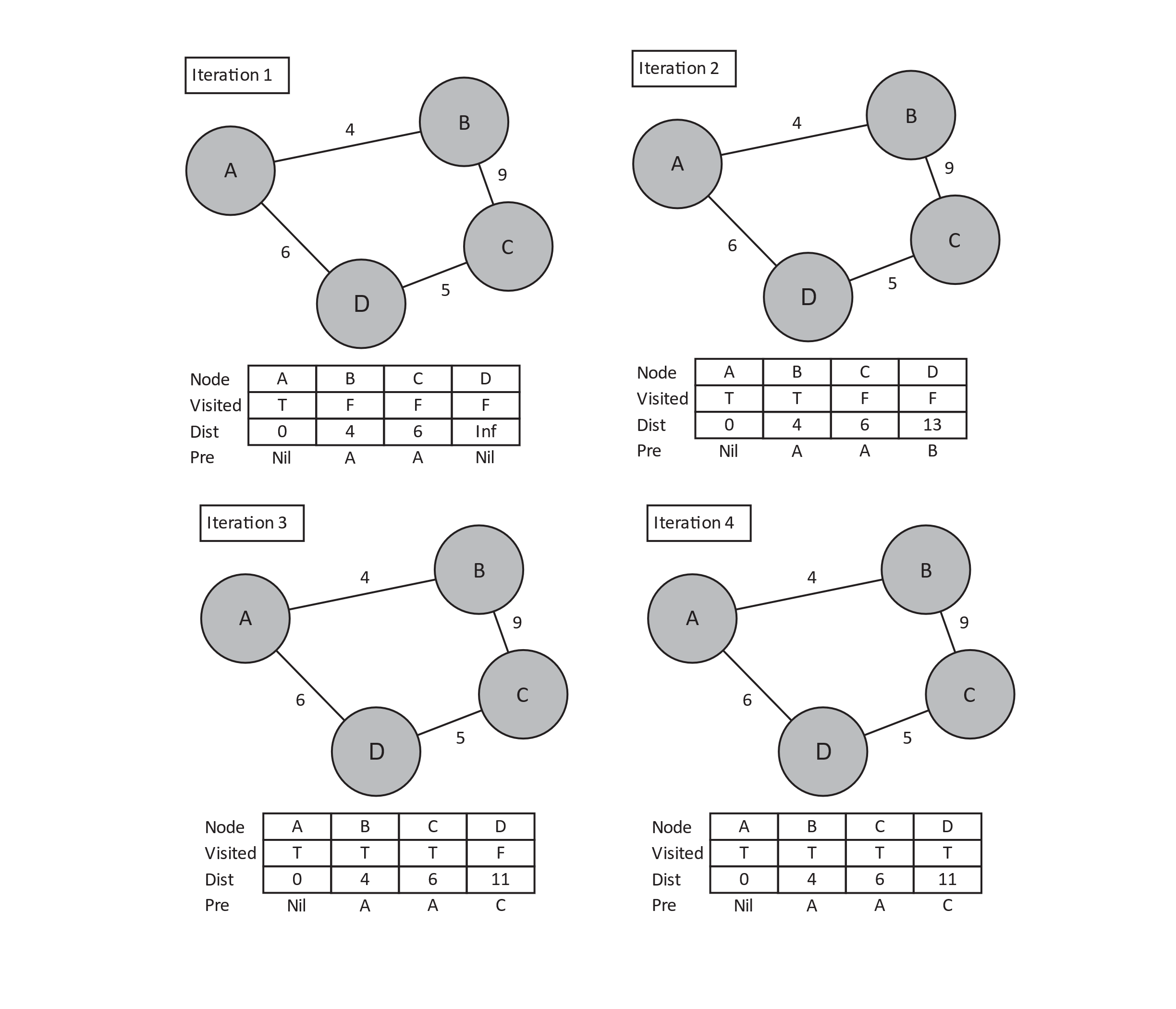
Figure 11.7

As with breadth first and depth first traversals, the precise runtime cannot be determined without specifying exactly how visited, distance, predecessors, and edges are structured. What we can determine with certainty is that the while-loop will iterate the same number of times as the number of nodes in the graph. This is evident because each iteration marks a node as visited, and the loop terminates when all nodes are visited. Assuming we are looking for all shortest paths (or our destination node is the last to be visited), we will perform the body of the inner loop once for each edge in the graph. This very closely approximates the runtime behavior of the traversal algorithms earlier and results in a likely worst-case runtime of O(N2). However, Dijkstra’s algorithm is well researched, and known improvements can be made to this runtime by choosing clever data structures to represent different components.
Minimum Spanning Trees (MSTs)
A Minimum Spanning Tree (MST) is a subgraph (subset of edges) that satisfies the following conditions:
- It must be a tree. In other words, there must be no cycles within the subgraph.
- It must be spanning, which means that all the nodes in the original graph exist in the subgraph and are reachable using only the edges in the subgraph.
- It is possible to have more than one spanning tree for a given graph. Of those possible spanning trees, the MST is the one with the lowest cumulative edge weight.
As with other graph properties and algorithms, MSTs have numerous applications in the natural world. The canonical example is that of a network broadcast. Imagine computers as nodes and the network connections between them as edges. In computer networking, we often want to be able to broadcast a message to all nodes on the network (or, put simply, ensure that all nodes receive a particular message). The MST represents the lowest-cost means of transmitting such a message. Note that this is not the fastest means of transmission. That would indeed be a tree created by running a single-source shortest-path algorithm like Dijkstra’s.
As with single-source shortest path, MSTs can be produced via numerous algorithms. The only one we address here is Prim’s. We do so due to its similarity with Dijkstra’s. Dijkstra’s produced shortest paths by comparing a known distance against the sum of the cumulative distance to the predecessor plus the newly considered edge (see line 11 in the pseudocode). This comparison can be made because the distance for a node denotes the shortest path we have considered so far. Prim’s algorithm changes the meaning of the distance value as well as the comparison on line 11. Rather than representing the cumulative distance as we did for shortest path, distance now represents the cost to add that node into the MST. The final change is simple: if we remove n.Dist from both lines 11 and 12, then we now find the MST rather than a shortest-path tree.
Exercises
- Imagine you have a sparse graph with a large number of nodes but a relatively small number of edges. You are working in a system with strict constraints on how much memory you can consume. How does this impact your decision between an adjacency matrix and an adjacency list?
- The breadth first example and pseudocode assume an unweighted and undirected graph. Does this pseudo code change if the graph is weighted? What if it is directed?
- Consider an array of numbers. Devise a way of sorting these numbers using the graph algorithms from this chapter. The challenging part here is to determine how to model the array as a graph. Hint: What if the numbers are nodes, each node is connected to each other node, and the weight is the difference between the two nodes’ values?
References
Levin, Ocsar. “Graph Theory.” In Discrete Mathematics: An Open Introduction, 3rd ed., chap. 4. 2019. http://discrete.openmathbooks.org/dmoi3/ch_graphtheory.html
